Сортировка данных в Excel по строкам и столбцам с помощью формул. Как проводилось тестирование. Сортировка по цвету ячейки и по шрифту
О том, что в текстовом процессоре Microsoft Word можно создавать таблицы, знают практически все более-менее активные пользователи этой программы. Да, здесь все не так профессионально реализовано, как в Excel, но для повседневных нужд возможностей текстового редактора более, чем достаточно. Нами уже довольно много написано об особенностях работы с таблицами в Ворде, и в этой статье мы рассмотрим еще одну тему.
Как отсортировать таблицу по алфавиту? Вероятнее всего, это не самый востребованный вопрос среди пользователей детища Майкрософт, но ответ на него уж точно знают далеко не все. В этой статье мы расскажем, как сортировать содержимое таблицы по алфавиту, а также о том, как выполнить сортировку в отдельном ее столбце.
1. Выделите таблицу со всем ее содержимым: для этого установите указатель курсора в ее левом верхнем углу, дождитесь появления знака перемещения таблицы ( — небольшой крестик, расположенный в квадрате) и кликните по нему.

2. Перейдите во вкладку «Макет» (раздел «Работа с таблицами» ) и нажмите на кнопку «Сортировка» , расположенную в группе «Данные» .

Примечание: Прежде, чем приступить к сортировке данных в таблице, рекомендуем вырезать или скопировать в другое место информацию, которая содержится в шапке (первой строке). Это не только упростит сортировку, но и позволит сохранить шапку таблицы на ее месте. Если положение первой строки таблицы для вас не принципиально, и она тоже должна быть отсортирована по алфавиту, выделяйте и ее. Также вы можете просто выделить таблицу без шапки.
3. Выберите в открывшемся окне необходимые параметры сортировки данных.

Если вам нужно, чтобы сортировка данных происходила относительно первого столбца, в разделах «Сортировать по», «Затем по», «Затем по» установите «Столбцам 1».

Если же каждый столбец таблицы должен быть отсортирован в алфавитном порядке, независимо от остальных столбцов, нужно сделать так:
- «Сортировать по» — «Столбцам 1»;
- «Затем по» — «Столбцам 2»;
- «Затем по» — «Столбцам 3».
Примечание: В нашем примере мы сортируем по алфавиту только первый столбец.
В случае с текстовыми данными, как в нашем примере, параметры «Тип» и «По» для каждой строки следует оставить без изменений («тексту» и «абзацам» , соответственно). Собственно, числовые данные по алфавиту сортировать попросту невозможно.

Последний столбец в окне «Сортировка» отвечает, собственно, за тип сортировки:
- «по возрастанию» — в алфавитном порядке (от «А» до «Я»);
- «по убыванию» — в обратном алфавитном порядке (от «Я» к «А»).

4. Задав необходимые значения, нажмите «ОК» , чтобы закрыть окно и увидеть изменения.

5. Данные в таблице будут отсортированы по алфавиту.
Не забудьте вернуть на свое место шапку. Кликните в первой ячейке таблицы и нажмите «CTRL+V» или кнопку «Вставить» в группе «Буфер обмена» (вкладка «Главная» ).

Сортировка отдельного столбца таблицы в алфавитном порядке
Иногда возникает необходимость отсортировать в алфавитном порядке данные только из одного столбца таблицы. Причем, сделать это нужно так, чтобы информация из всех остальных столбцов осталась на своем месте. Если дело касается исключительно первого столбца, можно воспользоваться вышеописанным методом, сделав это точно так же, как мы в своем примере. Если же это не первый столбец, выполните следующие действия:
1. Выделите столбец таблицы, который необходимо отсортировать по алфавиту.

2. Во вкладке «Макет» в группе инструментов «Данные» нажмите кнопку «Сортировка» .

3. В открывшемся окне в разделе «Сначала по» выберите начальный параметр сортировки:
- данные конкретной ячейки (в нашем примере это буква «Б»);
- укажите порядковый номер выделенного столбца;
- повторите аналогичное действие для разделов «Затем по».

Примечание: То, какой тип сортировки выбрать (параметры «Сортировать по» и «Затем по» ) зависит от данных в ячейках столбца. В нашем примере, когда в ячейках второго столбца указаны только буквы для алфавитной сортировки достаточно просто во всех разделах указать «Столбцам 2» . При этом, выполнять манипуляции, описанные ниже, необходимости нет.
4. В нижней части окна установите переключатель параметра «Список» в необходимое положение:
- «Строка заголовка»;
- «Без строки заголовка».

Примечание: Первый параметр «притягивает» к сортировке заголовок, второй — позволяет выполнить сортировку столбца без учета заголовка.
5. Нажмите расположенную внизу кнопку «Параметры» .
6. В разделе «Параметры сортировки» установите галочку напротив пункта «Только столбцы» .

7. Закрыв окно «Параметры сортировки» (кнопка «ОК»), убедитесь в том, что напротив всех пунктов тип сортировки установлен маркер «по возрастанию» (алфавитный порядок) или «по убыванию» (обратный алфавитный порядок).

8. Закройте окно, нажав «ОК» .

Выбранный вами столбец будет отсортирован в алфавитном порядке.
На этом все, теперь вы знаете, как отсортировать таблицу Ворд по алфавиту.
Создадим массив, в котором после завершения алгоритма будет лежать ответ. Будем поочередно вставлять элементы из исходного массива так, чтобы элементы в массиве-ответе всегда были отсортированы. Асимптотика в среднем и худшем случае – O(n 2), в лучшем – O(n). Реализовывать алгоритм удобнее по-другому (создавать новый массив и реально что-то вставлять в него относительно сложно): просто сделаем так, чтобы отсортирован был некоторый префикс исходного массива, вместо вставки будем менять текущий элемент с предыдущим, пока они стоят в неправильном порядке.Реализация:
void insertionsort(int* l, int* r) { for (int *i = l + 1; i < r; i++) { int* j = i; while (j > l && *(j - 1) > *j) { swap(*(j - 1), *j); j--; } } }
Сортировка Шелла / Shellsort
Используем ту же идею, что и сортировка с расческой, и применим к сортировке вставками. Зафиксируем некоторое расстояние. Тогда элементы массива разобьются на классы – в один класс попадают элементы, расстояние между которыми кратно зафиксированному расстоянию. Отсортируем сортировкой вставками каждый класс. В отличие от сортировки расческой, неизвестен оптимальный набор расстояний. Существует довольно много последовательностей с разными оценками. Последовательность Шелла – первый элемент равен длине массива, каждый следующий вдвое меньше предыдущего. Асимптотика в худшем случае – O(n 2). Последовательность Хиббарда – 2 n - 1, асимптотика в худшем случае – O(n 1,5), последовательность Седжвика (формула нетривиальна, можете ее посмотреть по ссылке ниже) - O(n 4/3), Пратта (все произведения степеней двойки и тройки) - O(nlog 2 n). Отмечу, что все эти последовательности нужно рассчитать только до размера массива и запускать от большего от меньшему (иначе получится просто сортировка вставками). Также я провел дополнительное исследование и протестировал разные последовательности вида s i = a * s i - 1 + k * s i - 1 (отчасти это было навеяно эмпирической последовательностью Циура – одной из лучших последовательностей расстояний для небольшого количества элементов). Наилучшими оказались последовательности с коэффициентами a = 3, k = 1/3; a = 4, k = 1/4 и a = 4, k = -1/5.Несколько полезных ссылок:
Реализации:
void shellsort(int* l, int* r) { int sz = r - l; int step = sz / 2; while (step > < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } step /= 2; } } void shellsorthib(int* l, int* r) { int sz = r - l; if (sz <= 1) return; int step = 1; while (step < sz) step <<= 1; step >>= 1; step--; while (step >= 1) { for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } step /= 2; } } int steps; void shellsortsedgwick(int* l, int* r) { int sz = r - l; steps = 1; int q = 1; while (steps * 3 < sz) { if (q % 2 == 0) steps[q] = 9 * (1 << q) - 9 * (1 << (q / 2)) + 1; else steps[q] = 8 * (1 << q) - 6 * (1 << ((q + 1) / 2)) + 1; q++; } q--; for (; q > < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void shellsortpratt(int* l, int* r) { int sz = r - l; steps = 1; int cur = 1, q = 1; for (int i = 1; i < sz; i++) { int cur = 1 << i; if (cur > sz / 2) break; for (int j = 1; j < sz; j++) { cur *= 3; if (cur > sz / 2) break; steps = cur; } } insertionsort(steps, steps + q); q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell1(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 4 + s / 4; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell2(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 3 + s / 3; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell3(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 4 - s / 5; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } }
Сортировка деревом / Tree sort
Будем вставлять элементы в двоичное дерево поиска. После того, как все элементы вставлены достаточно обойти дерево в глубину и получить отсортированный массив. Если использовать сбалансированное дерево, например красно-черное, асимптотика будет равна O(nlogn) в худшем, среднем и лучшем случае. В реализации использован контейнер multiset.Реализация:
void treesort(int* l, int* r) {
multiset
Гномья сортировка / Gnome sort
Алгоритм похож на сортировку вставками. Поддерживаем указатель на текущий элемент, если он больше предыдущего или он первый - смещаем указатель на позицию вправо, иначе меняем текущий и предыдущий элементы местами и смещаемся влево.Реализация:
void gnomesort(int* l, int* r) { int *i = l; while (i < r) { if (i == l || *(i - 1) <= *i) i++; else swap(*(i - 1), *i), i--; } }
Сортировка выбором / Selection sort
На очередной итерации будем находить минимум в массиве после текущего элемента и менять его с ним, если надо. Таким образом, после i-ой итерации первые i элементов будут стоять на своих местах. Асимптотика: O(n 2) в лучшем, среднем и худшем случае. Нужно отметить, что эту сортировку можно реализовать двумя способами – сохраняя минимум и его индекс или просто переставляя текущий элемент с рассматриваемым, если они стоят в неправильном порядке. Первый способ оказался немного быстрее, поэтому он и реализован.Реализация:
void selectionsort(int* l, int* r) { for (int *i = l; i < r; i++) { int minz = *i, *ind = i; for (int *j = i + 1; j < r; j++) { if (*j < minz) minz = *j, ind = j; } swap(*i, *ind); } }
Пирамидальная сортировка / Heapsort
Развитие идеи сортировки выбором. Воспользуемся структурой данных «куча» (или «пирамида», откуда и название алгоритма). Она позволяет получать минимум за O(1), добавляя элементы и извлекая минимум за O(logn). Таким образом, асимптотика O(nlogn) в худшем, среднем и лучшем случае. Реализовывал кучу я сам, хотя в С++ и есть контейнер priority_queue, поскольку этот контейнер довольно медленный.Реализация:
template
Быстрая сортировка / Quicksort
Выберем некоторый опорный элемент. После этого перекинем все элементы, меньшие его, налево, а большие – направо. Рекурсивно вызовемся от каждой из частей. В итоге получим отсортированный массив, так как каждый элемент меньше опорного стоял раньше каждого большего опорного. Асимптотика: O(nlogn) в среднем и лучшем случае, O(n 2). Наихудшая оценка достигается при неудачном выборе опорного элемента. Моя реализация этого алгоритма совершенно стандартна, идем одновременно слева и справа, находим пару элементов, таких, что левый элемент больше опорного, а правый меньше, и меняем их местами. Помимо чистой быстрой сортировки, участвовала в сравнении и сортировка, переходящая при малом количестве элементов на сортировку вставками. Константа подобрана тестированием, а сортировка вставками - наилучшая сортировка, подходящая для этой задачи (хотя не стоит из-за этого думать, что она самая быстрая из квадратичных).Реализация:
void quicksort(int* l, int* r) { if (r - l <= 1) return; int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll <= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quicksort(l, rr + 1); if (ll < r) quicksort(ll, r); } void quickinssort(int* l, int* r) { if (r - l <= 32) { insertionsort(l, r); return; } int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll <= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quickinssort(l, rr + 1); if (ll < r) quickinssort(ll, r); }
Сортировка слиянием / Merge sort
Сортировка, основанная на парадигме «разделяй и властвуй». Разделим массив пополам, рекурсивно отсортируем части, после чего выполним процедуру слияния: поддерживаем два указателя, один на текущий элемент первой части, второй – на текущий элемент второй части. Из этих двух элементов выбираем минимальный, вставляем в ответ и сдвигаем указатель, соответствующий минимуму. Слияние работает за O(n), уровней всего logn, поэтому асимптотика O(nlogn). Эффективно заранее создать временный массив и передать его в качестве аргумента функции. Эта сортировка рекурсивна, как и быстрая, а потому возможен переход на квадратичную при небольшом числе элементов.Реализация:
void merge(int* l, int* m, int* r, int* temp) { int *cl = l, *cr = m, cur = 0; while (cl < m && cr < r) { if (*cl < *cr) temp = *cl, cl++; else temp = *cr, cr++; } while (cl < m) temp = *cl, cl++; while (cr < r) temp = *cr, cr++; cur = 0; for (int* i = l; i < r; i++) *i = temp; } void _mergesort(int* l, int* r, int* temp) { if (r - l <= 1) return; int *m = l + (r - l) / 2; _mergesort(l, m, temp); _mergesort(m, r, temp); merge(l, m, r, temp); } void mergesort(int* l, int* r) { int* temp = new int; _mergesort(l, r, temp); delete temp; } void _mergeinssort(int* l, int* r, int* temp) { if (r - l <= 32) { insertionsort(l, r); return; } int *m = l + (r - l) / 2; _mergeinssort(l, m, temp); _mergeinssort(m, r, temp); merge(l, m, r, temp); } void mergeinssort(int* l, int* r) { int* temp = new int; _mergeinssort(l, r, temp); delete temp; }
Сортировка подсчетом / Counting sort
Создадим массив размера r – l, где l – минимальный, а r – максимальный элемент массива. После этого пройдем по массиву и подсчитаем количество вхождений каждого элемента. Теперь можно пройти по массиву значений и выписать каждое число столько раз, сколько нужно. Асимптотика – O(n + r - l). Можно модифицировать этот алгоритм, чтобы он стал стабильным: для этого определим место, где должно стоять очередное число (это просто префиксные суммы в массиве значений) и будем идти по исходному массиву слева направо, ставя элемент на правильное место и увеличивая позицию на 1. Эта сортировка не тестировалась, поскольку большинство тестов содержало достаточно большие числа, не позволяющие создать массив требуемого размера. Однако она, тем не менее, пригодилась.Блочная сортировка / Bucket sort
(также известна как корзинная и карманная сортировка). Пусть l – минимальный, а r – максимальный элемент массива. Разобьем элементы на блоки, в первом будут элементы от l до l + k, во втором – от l + k до l + 2k и т.д., где k = (r – l) / количество блоков. В общем-то, если количество блоков равно двум, то данный алгоритм превращается в разновидность быстрой сортировки. Асимптотика этого алгоритма неясна, время работы зависит и от входных данных, и от количества блоков. Утверждается, что на удачных данных время работы линейно. Реализация этого алгоритма оказалась одной из самых трудных задач. Можно сделать это так: просто создавать новые массивы, рекурсивно их сортировать и склеивать. Однако такой подход все же довольно медленный и меня не устроил. В эффективной реализации используется несколько идей:1) Не будем создавать новых массивов. Для этого воспользуемся техникой сортировки подсчетом – подсчитаем количество элементов в каждом блоке, префиксные суммы и, таким образом, позицию каждого элемента в массиве.
2) Не будем запускаться из пустых блоков. Занесем индексы непустых блоков в отдельный массив и запустимся только от них.
3) Проверим, отсортирован ли массив. Это не ухудшит время работы, так как все равно нужно сделать проход с целью нахождения минимума и максимума, однако позволит алгоритму ускориться на частично отсортированных данных, ведь элементы вставляются в новые блоки в том же порядке, что и в исходном массиве.
4) Поскольку алгоритм получился довольно громоздким, при небольшом количестве элементов он крайне неэффективен. До такой степени, что переход на сортировку вставками ускоряет работу примерно в 10 раз.
Осталось только понять, какое количество блоков нужно выбрать. На рандомизированных тестах мне удалось получить следующую оценку: 1500 блоков для 10 7 элементов и 3000 для 10 8 . Подобрать формулу не удалось – время работы ухудшалось в несколько раз.
Реализация:
void _newbucketsort(int* l, int* r, int* temp) { if (r - l <= 64) { insertionsort(l, r); return; } int minz = *l, maxz = *l; bool is_sorted = true; for (int *i = l + 1; i < r; i++) { minz = min(minz, *i); maxz = max(maxz, *i); if (*i < *(i - 1)) is_sorted = false; } if (is_sorted) return; int diff = maxz - minz + 1; int numbuckets; if (r - l <= 1e7) numbuckets = 1500; else numbuckets = 3000; int range = (diff + numbuckets - 1) / numbuckets; int* cnt = new int; for (int i = 0; i <= numbuckets; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; int ind = (*i - minz) / range; cnt++; } int sz = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= numbuckets; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = (temp - minz) / range; *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _newbucketsort(l + cnt, l + cnt[r], temp); else _newbucketsort(l, l + cnt[r], temp); } delete run; delete cnt; } void newbucketsort(int* l, int* r) { int *temp = new int; _newbucketsort(l, r, temp); delete temp; }
Поразрядная сортировка / Radix sort
(также известна как цифровая сортировка). Существует две версии этой сортировки, в которых, на мой взгляд, мало общего, кроме идеи воспользоваться представлением числа в какой-либо системе счисления (например, двоичной).LSD (least significant digit):
Представим каждое число в двоичном виде. На каждом шаге алгоритма будем сортировать числа таким образом, чтобы они были отсортированы по первым k * i битам, где k – некоторая константа. Из данного определения следует, что на каждом шаге достаточно стабильно сортировать элементы по новым k битам. Для этого идеально подходит сортировка подсчетом (необходимо 2 k памяти и времени, что немного при удачном выборе константы). Асимптотика: O(n), если считать, что числа фиксированного размера (а в противном случае нельзя было бы считать, что сравнение двух чисел выполняется за единицу времени). Реализация довольно проста.Реализация:
int digit(int n, int k, int N, int M) { return (n >> (N * k) & (M - 1)); } void _radixsort(int* l, int* r, int N) { int k = (32 + N - 1) / N; int M = 1 << N; int sz = r - l; int* b = new int; int* c = new int[M]; for (int i = 0; i < k; i++) { for (int j = 0; j < M; j++) c[j] = 0; for (int* j = l; j < r; j++) c++; for (int j = 1; j < M; j++) c[j] += c; for (int* j = r - 1; j >= l; j--) b[--c] = *j; int cur = 0; for (int* j = l; j < r; j++) *j = b; } delete b; delete c; } void radixsort(int* l, int* r) { _radixsort(l, r, 8); }
MSD (most significant digit):
На самом деле, некоторая разновидность блочной сортировки. В один блок будут попадать числа с равными k битами. Асимптотика такая же, как и у LSD версии. Реализация очень похожа на блочную сортировку, но проще. В ней используется функция digit, определенная в реализации LSD версии.Реализация:
void _radixsortmsd(int* l, int* r, int N, int d, int* temp) { if (d == -1) return; if (r - l <= 32) { insertionsort(l, r); return; } int M = 1 << N; int* cnt = new int; for (int i = 0; i <= M; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; cnt++; } int sz = 0; for (int i = 1; i <= M; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= M; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= M; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = digit(temp, d, N, M); *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _radixsortmsd(l + cnt, l + cnt[r], N, d - 1, temp); else _radixsortmsd(l, l + cnt[r], N, d - 1, temp); } delete run; delete cnt; } void radixsortmsd(int* l, int* r) { int* temp = new int; _radixsortmsd(l, r, 8, 3, temp); delete temp; }
Битонная сортировка / Bitonic sort:
Идея данного алгоритма заключается в том, что исходный массив преобразуется в битонную последовательность – последовательность, которая сначала возрастает, а потом убывает. Ее можно эффективно отсортировать следующим образом: разобьем массив на две части, создадим два массива, в первый добавим все элементы, равные минимуму из соответственных элементов каждой из двух частей, а во второй – равные максимуму. Утверждается, что получатся две битонные последовательности, каждую из которых можно рекурсивно отсортировать тем же образом, после чего можно склеить два массива (так как любой элемент первого меньше или равен любого элемента второго). Для того, чтобы преобразовать исходный массив в битонную последовательность, сделаем следующее: если массив состоит из двух элементов, можно просто завершиться, иначе разделим массив пополам, рекурсивно вызовем от половинок алгоритм, после чего отсортируем первую часть по порядку, вторую в обратном порядке и склеим. Очевидно, получится битонная последовательность. Асимптотика: O(nlog 2 n), поскольку при построении битонной последовательности мы использовали сортировку, работающую за O(nlogn), а всего уровней было logn. Также заметим, что размер массива должен быть равен степени двойки, так что, возможно, придется его дополнять фиктивными элементами (что не влияет на асимптотику).Реализация:
void bitseqsort(int* l, int* r, bool inv) { if (r - l <= 1) return; int *m = l + (r - l) / 2; for (int *i = l, *j = m; i < m && j < r; i++, j++) { if (inv ^ (*i > *j)) swap(*i, *j); } bitseqsort(l, m, inv); bitseqsort(m, r, inv); } void makebitonic(int* l, int* r) { if (r - l <= 1) return; int *m = l + (r - l) / 2; makebitonic(l, m); bitseqsort(l, m, 0); makebitonic(m, r); bitseqsort(m, r, 1); } void bitonicsort(int* l, int* r) { int n = 1; int inf = *max_element(l, r) + 1; while (n < r - l) n *= 2; int* a = new int[n]; int cur = 0; for (int *i = l; i < r; i++) a = *i; while (cur < n) a = inf; makebitonic(a, a + n); bitseqsort(a, a + n, 0); cur = 0; for (int *i = l; i < r; i++) *i = a; delete a; }
Timsort
Гибридная сортировка, совмещающая сортировку вставками и сортировку слиянием. Разобьем элементы массива на несколько подмассивов небольшого размера, при этом будем расширять подмассив, пока элементы в нем отсортированы. Отсортируем подмассивы сортировкой вставками, пользуясь тем, что она эффективно работает на отсортированных массивах. Далее будем сливать подмассивы как в сортировке слиянием, беря их примерно равного размера (иначе время работы приблизится к квадратичному). Для этого удобного хранить подмассивы в стеке, поддерживая инвариант - чем дальше от вершины, тем больше размер, и сливать подмассивы на верхушке только тогда, когда размер третьего по отдаленности от вершины подмассива больше или равен сумме их размеров. Асимптотика: O(n) в лучшем случае и O(nlogn) в среднем и худшем случае. Реализация нетривиальна, твердой уверенности в ней у меня нет, однако время работы она показала довольно неплохое и согласующееся с моими представлениями о том, как должна работать эта сортировка.Подробнее timsort описан здесь:
Реализация:
void _timsort(int* l, int* r, int* temp) {
int sz = r - l;
if (sz <= 64) {
insertionsort(l, r);
return;
}
int minrun = sz, f = 0;
while (minrun >= 64) {
f |= minrun & 1;
minrun >>= 1;
}
minrun += f;
int* cur = l;
stack
Тестирование
Железо и система
Процессор: Intel Core i7-3770 CPU 3.40 GHzОЗУ: 8 ГБ
Тестирование проводилось на почти чистой системе Windows 10 x64, установленной за несколько дней до запуска. Использованная IDE – Microsoft Visual Studio 2015.
Тесты
Все тесты поделены на четыре группы. Первая группа – массив случайных чисел по разным модулям (10, 1000, 10 5 , 10 7 и 10 9). Вторая группа – массив, разбивающийся на несколько отсортированных подмассивов. Фактически брался массив случайных чисел по модулю 10 9 , а далее отсортировывались подмассивы размера, равного минимуму из длины оставшегося суффикса и случайного числа по модулю некоторой константы. Последовательность констант – 10, 100, 1000 и т.д. вплоть до размера массива. Третья группа – изначально отсортированный массив случайных чисел с некоторым числом «свопов» - перестановок двух случайных элементов. Последовательность количеств свопов такая же, как и в предыдущей группе. Наконец, последняя группа состоит из нескольких тестов с полностью отсортированным массивом (в прямом и обратном порядке), нескольких тестов с исходным массивом натуральных чисел от 1 до n, в котором несколько чисел заменены на случайное, и тестов с большим количеством повторений одного элемента (10%, 25%, 50%, 75% и 90%). Таким образом, тесты позволяют посмотреть, как сортировки работают на случайных и частично отсортированных массивах, что выглядит наиболее существенным. Четвертая группа во многом направлена против сортировок с линейным временем работы, которые любят последовательности случайных чисел. В конце статьи есть ссылка на файл, в котором подробно описаны все тесты.Размер входных данных
Было бы довольно глупо сравнивать, например, сортировку с линейным временем работы и квадратичную, и запускать их на тестах одного размера. Поэтому каждая из групп тестов делится еще на четыре группы, размера 10 5 , 10 6 , 10 7 и 10 8 элементов. Сортировки были разбиты на три группы, в первой – квадратичные (сортировка пузырьком, вставками, выбором, шейкерная и гномья), во второй – нечто среднее между логарифмическим временем и квадратом, (битонная, несколько видов сортировки Шелла и сортировка деревом), в третьей все остальные. Кого-то, возможно, удивит, что сортировка деревом попала не в третью группу, хотя ее асимптотика и O(nlogn), но, к сожалению, ее константа очень велика. Сортировки первой группы тестировались на тестах с 10 5 элементов, второй группы – на тестах с 10 6 и 10 7 , третьей – на тестах с 10 7 и 10 8 . Именно такие размеры данных позволяют как-то увидеть рост времени работы, при меньших размерах слишком велика погрешность, при больших алгоритм работает слишком долго (или же недостаток оперативной памяти). С первой группой я не стал заморачиваться, чтобы не нарушать десятикратное увеличение (10 4 элементов для квадратичных сортировок слишком мало), в конце концов, сами по себе они представляют мало интереса.Как проводилось тестирование
На каждом тесте было производилось 20 запусков, итоговое время работы – среднее по получившимся значениям. Почти все результаты были получены после одного запуска программы, однако из-за нескольких ошибок в коде и системных глюков (все же тестирование продолжалось почти неделю чистого времени) некоторые сортировки и тесты пришлось впоследствии перетестировать.Тонкости реализации
Возможно, кого-то удивит, что в реализации самого процесса тестирования я не использовал указатели на функции, что сильно сократило бы код. Оказалось, что это заметно замедляет работу алгоритма (примерно на 5-10%). Поэтому я использовал отдельный вызов каждой функции (это, конечно, не отразилось бы на относительной скорости, но… все же хочется улучшить и абсолютную). По той же причине были заменены векторы на обычные массивы, не были использованы шаблоны и функции-компараторы. Все это более актуально для промышленного использования алгоритма, нежели его тестирования.Результаты
Все результаты доступны в нескольких видах – три диаграммы (гистограмма, на которой видно изменение скорости при переходе к следующему ограничению на одном типе тестов, график, изображающий то же самое, но иногда более наглядно, и гистограмма, на которой видно, какая сортировка лучше всего работает на каком-то типе тестов) и таблицы, на которых они основаны. Третья группа была разделена еще на три части, а то мало что было бы понятно. Впрочем, и так далеко не все диаграммы удачны (в полезности третьего типа диаграмм я вообще сильно сомневаюсь), но, надеюсь, каждый сможет найти наиболее подходящую для понимания.Поскольку картинок очень много, они скрыты спойлерами. Немного комментариев по поводу обозначений. Сортировки названы так, как выше, если это сортировка Шелла, то в скобочках указан автор последовательности, к названиям сортировок, переходящих на сортировку вставками, приписано Ins (для компактности). В диаграммах у второй группы тестов обозначена возможная длина отсортированных подмассивов, у третьей группы - количество свопов, у четвертой - количество замен. Общий результат рассчитывался как среднее по четырем группам.
Первая группа сортировок
Массив случайных чисел
Таблицы



Совсем скучные результаты, даже частичная отсортированность при небольшом модуле почти незаметна.
Таблицы




Уже гораздо интереснее. Обменные сортировки наиболее бурно отреагировали, шейкерная даже обогнала гномью. Сортировка вставками ускорилась только под самый конец. Сортировка выбором, конечно, работает совершенно также.
Свопы
Таблицы





Здесь наконец-то проявила себя сортировка вставками, хотя рост скорости у шейкерной примерно такой же. Здесь проявилась слабость сортировки пузырьком - достаточно одного свопа, перемещающего маленький элемент в конец, и она уже работает медленно. Сортировка выбором оказалась почти в конце.
Изменения в перестановке
Таблицы





Группа почти ничем не отличается от предыдущей, поэтому результаты похожи. Однако сортировка пузырьком вырывается вперед, так как случайный элемент, вставленный в массив, скорее всего будет больше всех остальных, то есть за одну итерацию переместится в конец. Сортировка выбором стала аутсайдером.
Повторы
Таблицы





Здесь все сортировки (кроме, конечно, сортировки выбором) работали почти одинаково, ускоряясь по мере увеличении количества повторов.
Итоговые результаты

За счет своего абсолютного безразличия к массиву, сортировка выбором, работавшая быстрее всех на случайных данных, все же проиграла сортировке вставками. Гномья сортировка оказалась заметно хуже последней, из-за чего ее практическое применение сомнительно. Шейкерная и пузырьковая сортировки оказались медленнее всех.
Вторая группа сортировок
Массив случайных чисел
Таблицы, 1е6 элементов




Сортировка Шелла с последовательностью Пратта ведет себя совсем странно, остальные более менее ясно. Сортировка деревом любит частично отсортированные массивы, но не любит повторов, возможно, поэтому самое худшее время работы именно посередине.
Таблицы, 1е7 элементов




Все как прежде, только Шелл с Праттом усилился на второй группе из-за отсортированности. Также становится заметным влияние асимптотики - сортировка деревом оказывается на втором месте, в отличие от группы с меньшим числом элементов.
Частично отсортированный массив
Таблицы, 1е6 элементов




Здесь понятным образом ведут себя все сортировки, кроме Шелла с Хиббардом, который почему-то не сразу начинает ускоряться.
Таблицы, 1е7 элементов




Здесь все, в общем, как и прежде. Даже асимптотика сортировки деревом не помогла ей вырваться с последнего места.
Свопы
Таблицы, 1е6 элементов





Таблицы, 1е7 элементов




Здесь заметно, что у сортировок Шелла большая зависимость от частичной отсортированности, так как они ведут себя практически линейно, а остальные две только сильно падают на последних группах.
Изменения в перестановке
Таблицы, 1е6 элементов




Таблицы, 1е7 элементов




Здесь все похоже на предыдущую группу.
Повторы
Таблицы, 1е6 элементов




Опять все сортировки продемонстрировали удивительную сбалансированность, даже битонная, которая, казалось бы, почти не зависит от массива.
Таблицы, 1е7 элементов




Ничего интересного.
Итоговые результаты


Убедительное первое место заняла сортировка Шелла по Хиббарду, не уступив ни в одной промежуточной группе. Возможно, стоило ее отправить в первую группу сортировок, но… она слишком слаба для этого, да и тогда почти никого не было бы в группе. Битонная сортировка довольно уверенно заняла второе место. Третье место при миллионе элементах заняла другая сортировка Шелла, а при десяти миллионах сортировка деревом (асимптотика сказалась). Стоит обратить внимание, что при десятикратном увеличении размера входных данных все алгоритмы, кроме древесной сортировки, замедлились почти в 20 раз, а последняя всего лишь в 13.
Третья группа сортировок
Массив случайных чисел
Таблицы, 1е7 элементов











Таблицы, 1е8 элементов











Почти все сортировки этой группы имеют почти одинаковую динамику. Почему же почти все сортировки ускоряются, когда массив частично отсортирован? Обменные сортировки работают быстрее потому, что надо делать меньше обменов, в сортировке Шелла выполняется сортировка вставками, которая сильно ускоряется на таких массивах, в пирамидальной сортировке при вставке элементов сразу завершается просеивание, в сортировке слиянием выполняется в лучшем случае вдвое меньше сравнений. Блочная сортировка работает тем лучше, чем меньше разность между минимальным и максимальным элементом. Принципиально отличается только поразрядная сортировка, которой все это безразлично. LSD-версия работает тем лучше, чем больший модуль. Динамика MSD-версия мне не ясна, то, что она сработала быстрее чем LSD удивило.
Частично отсортированный массив
Таблицы, 1е7 элементов











Таблицы, 1е8 элементов











Здесь все тоже довольно понятно. Стало заметен алгоритм Timsort, на него отсортированность действует сильнее, чем на остальные. Это позволило этому алгоритму почти сравняться с оптимизированной версией быстрой сортировки. Блочная сортировка, несмотря на улучшение времени работы при частичной отсортированности, не смогла обогнать поразрядную сортировку.
Откройте в проводнике папку «Документы» и отсортируйте содержимое по дате изменения. Что у вас сверху – папки или файлы? Правильный ответ зависит от того, как вы открыли папку:)
Постоянные читатели уже догадались, что сегодня не обойдется без – интересной, но так толком и не прижившейся . Казалось бы, в Windows 10 библиотеки ушли на второй план, но на них очень много завязано.
Сегодня в программе
О роли библиотек в Windows 10
Действительно, в проводнике папки Документы, Изображения и Музыка оккупировали Компьютер и панель быстрого запуска, а библиотеки скрылись из области навигации. Но на них полагается история файлов (как мы выяснили в предыдущей записи) и унаследованное из Windows 7 резервное копирование образов (со старыми граблями).
А главное – библиотеки присутствуют в стандартных диалогах , причем окно открывается именно в библиотеке , в том числе в магазинных приложениях.
В качестве источника фотографий предлагается добавить папку из библиотеки Документы в библиотеку Изображения
При этом Microsoft так и не удалось вживить библиотеки в оболочку, и сегодня я разберу очередную путаницу.
Нестыковка сортировки
В зависимости от того, открываете вы папку из библиотеки или минуя ее, может варьироваться не только внешний вид , но и сортировка по дате. Проведите простой эксперимент (результат ниже верен при стандартных настройках проводника):
- Откройте папку с документами из области навигации или Win + R → Documents и отсортируйте ее по дате изменения. Недавние файлы окажутся вверху списка.
- Откройте эту же папку из библиотеки: Win + R → shell:documentsLibrary и выполните такую же сортировку. Здесь вверху списка папки, и надо прокрутить их вниз, чтобы добраться до файлов.
По адресной строке легко определить, открыта папка из библиотеки или напрямую (это я разбирал в викторине еще 5 лет назад).
 Разница в сортировке по дате изменения между папками и библиотеками при стандартных настройках проводника
Разница в сортировке по дате изменения между папками и библиотеками при стандартных настройках проводника
Имеет смысл привести настройки к единому виду, чтобы не путаться. Это полезно даже в случае, если вы не пользуетесь библиотеками намеренно, поскольку вы будете на них натыкаться в диалоговых окнах классических и магазинных приложений.
Вопрос лишь в том, какой способ отображения результатов вам милее!
Уверен, что опытные пользователи часто используют первый вариант – с файлами вверху. Сортируя по дате, мы все-таки чаще ищем файл в известной папке, и нет смысла крутить колесо мыши лишний раз. Но вариант с папками сверху имеет право на жизнь, поэтому я к нему вернусь, когда разберусь с библиотеками.
Сортировка в библиотеках
Можно долго ломать голову, если не знать про одну особенность библиотек. Когда вы открываете папку из библиотеки, наряду с группировкой и сортировкой появляется возможность упорядочивания файлов, о которой я рассказывал в классической серии пенальти «Проводник vs. TC».
Интересно, что в Windows 7 упорядочивание было вынесено на специальную библиотечную панель вверху окна проводника. Но Windows 8 он сильно обновился , и упорядочивание осталось только в контекстном меню.
Библиотеки: сортировка по дате – «файлы всегда вверху»
Щелкните ПКМ на свободном месте в папке. А вот и причина того, что в библиотеках папки всегда находятся сверху – по ним ведется упорядочивание!
 Контекстное меню фона папки, открытой из библиотеки
Контекстное меню фона папки, открытой из библиотеки
Переключите упорядочивание на Имя и отсортируйте папку по дате изменения. Теперь недавние файлы сверху, что и требовалось доказать!
Сортировка в папках
Сейчас будет интереснее! Допустим, вы скачали в папку Movies седьмой сезон любимого сериала, все эпизоды которого легли во вложенную папку. В корне Movies у вас много отдельных файлов — фильмы, торрент-файлы и т.д. Обычная сортировка по дате тут не помогает, потому что папки оседают внизу — под файлами.
 Обычная сортировка папки по дате в папке
Обычная сортировка папки по дате в папке
Сортировка по имени поднимет папки вверх, но свежая папка затеряется в их списке, и все равно придется искать ее глазами.
Папки: сортировка по дате – «папки всегда вверху»
Секретное решение заложено в проводник со времен Windows Vista.
- Щелкните столбец Дата изменения , чтобы новое было сверху.
- Удерживая Shift , щелкните столбец Тип (также сработает Имя ).
Сверху отобразятся папки, отсортированные по дате, и свежая папка будет в самом верху!
 Индикатор сортировки в проводнике всегда указывает на основной столбец, а дополнительные критерии никак не обозначены
Индикатор сортировки в проводнике всегда указывает на основной столбец, а дополнительные критерии никак не обозначены
Проводник запоминает комбинированное состояние сортировки, но его можно сбросить – сначала удерживая Ctrl , щелкните по тому же столбцу, а потом отсортируйте по дате изменения как обычно.
Папки: сортировка по нескольким критериям
Сортировка по дате – это самая распространенная постановка вопроса, но трюк с Shift работает с любыми столбцами, причем вы можете применить одновременно несколько критериев сортировки!
Чтобы продемонстрировать это, я сгенерировал полтора десятка файлов двух типов с разными размерами и датами создания, а для наглядности сделал GIF с четырьмя состояниями сортировки.
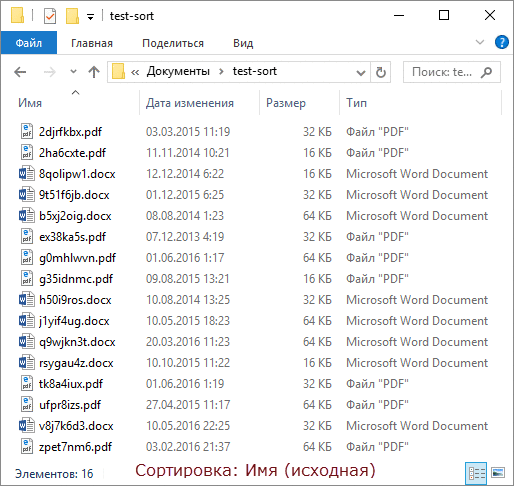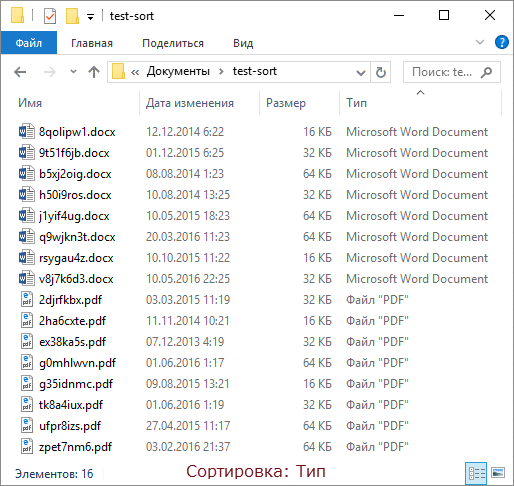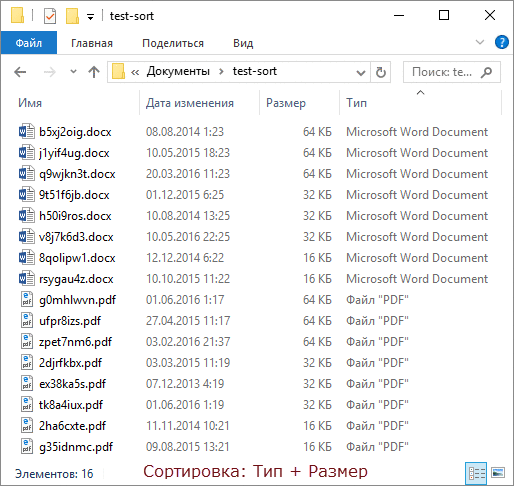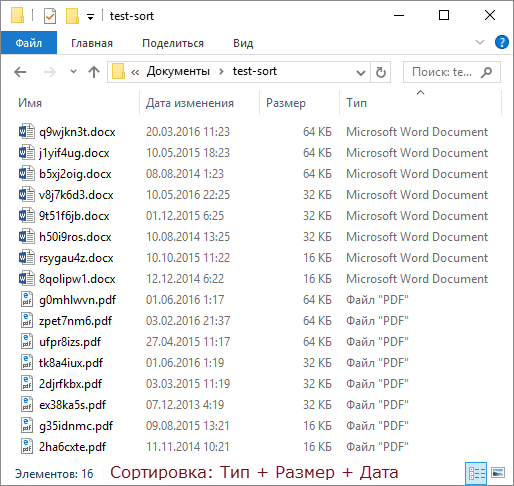
По порядку фреймов:
- В исходном состоянии папки отсортированы по имени.
- Сортируем по типу обычным способом.
- Сортируем с Shift по размеру, и файлы каждого типа выстраиваются по убыванию размера.
- Сортируем с Shift по дате изменения, и файлы одного размера выстраиваются от новых к старым!
Работает! :)
Бонус: сортировка в Total Commander
Дочитав статью до этого места, некоторые из вас, думаю, уже проверили, работает ли прием с Shift в любимом файловом менеджере. Total Commander так тоже умеет! Причем у него реализация более наглядная.
 У Total Commander в столбцах появляются стрелки и порядковый номер сортировки, а основной столбец выделен цветом
У Total Commander в столбцах появляются стрелки и порядковый номер сортировки, а основной столбец выделен цветом
Думаю, это должно работать и в других двухпанельных менеджерах – напишите в комментариях!
Грабли
Есть пара моментов, которые нужно учитывать.
- В проводнике у трюка с Shift есть ограничение – он не работает при активной панели просмотра, но она быстро переключается по Alt + P .
- Применительно к сортировке по дате вместо этого фокуса в сети встречаются советы использовать столбец Дата вместо Дата изменения . Это чревато тем, созданный год назад и скачанный сегодня документ не окажется вверху списка.
История вопроса
Обычно, этот подзаголовок я использую для рассказа об эволюции той или иной фичи, но сегодня я вас развлеку историей о нелегком пути этой статьи на свет.
Вопрос про библиотеки мне задал в почте читатель Евгений К . Порывшись в блоге, я выяснил, что конкретного решения не публиковал, а на новую отдельную статью оно не тянуло. Я скинул ответ почтой и сделал себе пометку написать о нем в соцсетях . Но мысль о том, что я уже писал на эту тему крепко засела в голове.
Я прошерстил OneNote и нашел упоминание о сортировке с Shift ! Оно оказалось в набросках к опубликованной четыре (!) года назад статье 14 способов использования мыши в связке с клавиатурой для ускорения работы . Очевидно, я тогда решил, что трюк заслуживает отдельного материала в продолжение темы (и даже сделал пометку ToDo:)
Наброски к записи 2012 года в архиве OneNote
Теперь я доставил вам и пятнадцатый способ:) Лучше поздно, чем никогда!
Дискуссия
Мы уже столько раз обсуждали файловые менеджеры и проводник в частности, что трудно придумать новую тему для дискуссии. В комментариях:
- напишите знали ли вы об этом трюке сортировки и насколько он вам [будет] полезен в повседневных задачах
- поделитесь приемами, которые вы применяете, когда нужно максимально быстро добраться до нужных файлов или папок, в т.ч. в окнах Открыть/Сохранить как
В Access существует несколько способов сортировки данных, отобранных посредством запроса. Быстро выполнить сортировку в окне запроса позволяют команда Сортировка из меню Записи, а также кнопки По возрастанию и По убыванию панели инструментов. Для этого следует включить в запрос поля таблицы, по которым будут рассортированы записи, и определить способ сортировки - по возрастанию или по убыванию. Данные можно упорядочить по алфавиту, а также по убыванию или возрастанию. При алфавитно-цифровой сортировке по возрастанию данные сортируются в таком порядке: сначала - элементы, начинающиеся со знаков пунктуации или специальных символов, затем - элементы, начинающиеся с цифр, а затем - элементы, которые начинаются с букв.
Сортировка данных в таблице по содержимому только одного столбца не всегда приводит к желаемым результатам, поэтому иногда требуется осуществлять сортировку по содержимому нескольких полей.
Примечание: Чтобы ускорить сортировку, следует размещать рядом поля, данные которых необходимо рассортировать.
Через окно запроса в исходную таблицу можно вставить новые записи, как при заполнении таблицы. Добавляемые или изменяемые данные помещаются в таблицу, на основе которой создан запрос. В результате ввода новых данных в таблицу может нарушиться порядок следования данных в запросе. Для восстановления порядка необходимо повторить вызов запроса и сортировку данных.
Выполнить сортировку данных можно и в окне конструктора запросов. Для этого необходимо нажать кнопку Открыть на вкладке Запросы окна базы данных. В окне выбора таблиц отметить имя таблицы, в которой следует выполнить сортировку данных, после чего нажать кнопки Добавить и Закрыть. Отметить в списке все имена полей, дважды щелкнув на заголовке списка, и переместить его в QBE-область. Для нужного поля задать в строке Сортировка способ сортировки. Сохранить запрос.
Применение специальных критериев
До сих пор мы рассматривали запросы, выполняющие отбор полей таблицы. При создании запроса можно задать дополнительные критерии, вследствие чего он будет осуществлять отбор только нужных сведений в каждом поле.Для формирования такого запроса необходимо в QBE-области ввести значение в ячейку, расположенную на пересечении строки Условия отбора и колонки с нужным именем.
Критерии, устанавливаемые в QBE-области, необходимо заключать в кавычки. Если Access идентифицирует введенные символы как критерий отбора, то заключает их в кавычки автоматически, а если нет, то сообщает о синтаксической ошибке. Программа Access не может распознать как критерий комбинацию символов и знаков подстановки.
Примечание: В запросах символы подстановки * и? применяются так же, как и во всех приложениях Microsoft Office 97. Символ звездочки заменяет любое количество букв или цифр, а знак вопроса - только один символ.
Все строки в QBE-области, расположенные под строкой Условия отбора , служат для задания критериев отбора. Таким образом, для одного поля можно определить два, три и более критериев отбора данных. По умолчанию все элементы критерия объединяются оператором ИЛИ . Это значит, что запрос выберет те записи, которые соответствуют хотя бы одному критерию.
Чтобы объединить несколько условий отбора оператором И , следует привести их в одной строке. Например, если необходимо выбрать записи из таблицы Зарплата , в которых указаны оклады от 310 до 1500, то в столбце Оклад надлежит ввести следующий критерий: Bet ween 310 and 1500 . Другой формой записи этого критерия является выражение > 310 And <1500 .
В результате будут отобраны только те записи, которые удовлетворяют обоим условиям, т.е. оклады, значения которых находятся в интервале от 310 до 1500.
Если необходимо отобрать несколько диапазонов значений, то критерий для каждого диапазона следует указать в отдельной строке.
Исключить группу данных из состава анализируемых запросом записей (например, оклад 400) позволяет следующий критерий: Not 400 . Другая форма записи этого критерия: <>400 . В этом случае можно не использовать кавычки.
ОператорыAnd иOr применяются как отдельно, так и совместно. Следует помнить, что условия, связанные операторомAnd , выполняются раньше условий, объединенных операторомOr .
При выборке данных бывает важно получить их в определенном упорядоченном виде. Сортировка может быть выполнена по любым полям с любым типом данных. Это может быть сортировка по возрастанию или убыванию для числовых полей. Для символьных (текстовых) полей это может быть сортировка в алфавитном порядке, хотя по сути, она так же является сортировкой по возрастанию или убыванию. Она так же может быть выполнена в любых направлениях – от А, до Я, и наоборот от Я, до А.
Суть процесса сортировки заключается к приведению последовательности к определенному порядку. Подробней о сортировки можно узнать в статье "Алгоритмы сортировки" Например, сортировка произвольной числовой последовательности по возрастанию:
2, 4, 1, 5, 9
должна привести к упорядоченной последовательности:
1, 2, 4, 5, 6
Аналогично, при сортировке по возрастанию строковых значений:
Иванов Иван, Петров Петр, Иванов Андрей
результат должен быть:
Иванов Андрей, Иванов Иван, Петров Петр
Здесь строка "Иванов Андрей" перешла в начало, так как сравнение строк производится посимвольно. Обе строки начинаются одинаковых символов "Иванов ". Так как символ "А" в слове "Андрей" идет раньше в алфавите, чем символ "И" в слове "Иван", то эта строка будет поставлена раньше.
Сортировка в запросе SQL
Для выполнения сортировки в строку запроса нужно добавить команду ORDER BY. После этой команды указывается поле, по которому производится сортировка.
Для примеров используем таблицу товаров goods:
| num
(номер товара) | title
(название) | price
(цена) |
| 1 | Мандарин | 50 |
| 2 | Арбуз | 120 |
| 3 | Ананас | 80 |
| 4 | Банан | 40 |
Данные здесь уже упорядочены по столбцу "num". Теперь, построим запрос, который выведет таблицу с товарами, упорядоченными в алфавитном порядке:
SELECT * FROM goods ORDER BY title
SELECT * FROM goods – указывает выбрать все поля из таблицы goods;
ORDER BY – команда сортировки;
title – столбец, по которому будет выполняться сортировка.
Результат выполнения такого запроса следующий:
| num | title | price |
| 3 | Ананас | 80 |
| 2 | Арбуз | 120 |
| 4 | Банан | 40 |
| 1 | Мандарин | 50 |
Так же можно выполнить сортировку для любого из полей таблицы.
Направление сортировки
По умолчанию, команда ORDER BY выполняет сортировку по возрастанию. Чтобы управлять направлением сортировки вручную, после имени столбца указывается ключевое слово ASC (по возрастанию) или DESC (по убыванию). Таким образом, чтобы вывести нашу таблицу в порядке убывания цен, нужно задать запрос так:
SELECT * FROM goods ORDER BY price DESC
Сортировка по возрастанию цены будет:
SELECT * FROM goods ORDER BY price ASC
Сортировка по нескольким полям
SQL допускает сортировку сразу по нескольким полям. Для этого после команды ORDER BY необходимые поля указываются через запятую. Порядок в результате запроса будет настраиваться в той же очередности, в которой указаны поля сортировки.
| column1 | column2 | column3 |
| 3 | 1 | c |
| 1 | 3 | c |
| 2 | 2 | b |
| 2 | 1 | b |
| 1 | 2 | a |
| 1 | 3 | a |
| 3 | 4 | a |
Отсортируем таблицу по следующим правилам:
SELECT * FROM mytable ORDER BY column1 ASC, column2 DESC, column3 ASC
Т.е. первый столбец по возрастанию, второй по убыванию, третий опять по возрастанию. Запрос упорядочит строки по первому столбцу, затем, не разрушая первого правила, по второму столбцу. Затем, так же, не нарушая имеющихся правил, по третьему. В результате получится такой набор данных:
| column1 | column2 | column3 |
| 1 | 3 | a |
| 1 | 3 | c |
| 1 | 2 | a |
| 2 | 2 | b |
| 2 | 1 | b |
| 3 | 1 | a |
| 3 | 1 | c |
Порядок команды ORDER BY в запросе
Сортировка строк чаще всего проводится вместе с условием на выборку данных. Команда ORDER BY ставится после условия выборки WHERE. Например, выбираем товары с ценой меньше 100 рублей, упорядочив по названию в алфавитном порядке:
SELECT * FROM goods WHERE price 100 ORDER BY price ASC
Похожие записи:
 Монокуляры с большой кратностью - особенности и преимущества Монокуляр увеличение 50
Монокуляры с большой кратностью - особенности и преимущества Монокуляр увеличение 50
 World of Tanks вылетает при запуске — исправляем ошибки World of tanks вылетает после каждого боя
World of Tanks вылетает при запуске — исправляем ошибки World of tanks вылетает после каждого боя
 Серверный ключ 1с по сети
Серверный ключ 1с по сети
 Как включается WiFi на ноутбуках Добавить новую беспроводную сеть на ноутбук
Как включается WiFi на ноутбуках Добавить новую беспроводную сеть на ноутбук
 Как узнать серийный номер iPhone?
Как узнать серийный номер iPhone?