Download robots txt for yandex. How to edit robots txt file. User-agent with empty value
We have released a new book, "Content Marketing on Social Media: How to Get Into the Heads of Subscribers and Fall in Love with Your Brand."

Robots.txt is a text file containing information for crawlers to help index portal pages.
More videos on our channel - learn internet marketing with SEMANTICA
![]()
Imagine that you are on an island treasure hunt. You have a map. The route is indicated there: “Come to a large stump. From it, take 10 steps to the east, then walk to the cliff. Turn right, find a cave. "
These are directions. Following them, you follow the route and find a treasure. The search bot works in a similar way when it starts indexing a site or page. It finds the robots.txt file. It reads out which pages should be indexed and which should not. And, following these commands, he bypasses the portal and adds its pages to the index.
What is robots.txt for?
They begin to go to sites and index pages after the site is uploaded to the hosting and dns are registered. They do their job regardless of whether you have any technical files or not. Robots instructs search engines that when crawling a website, they need to take into account the parameters that it contains.
The absence of a robots.txt file can lead to problems with the crawl speed of the site and the presence of garbage in the index. Incorrect configuration of the file is fraught with the exclusion of important parts of the resource from the index and the presence of unnecessary pages in the output.
All this, as a result, leads to problems with promotion.
Let's take a closer look at what instructions are contained in this file, how they affect the behavior of the bot on your site.
How to make robots.txt
First, check if you have this file.
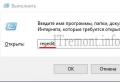
Enter the website address in the address bar of the browser and the file name separated by a slash, for example, https://www.xxxxx.ru/robots.txt
If the file is present, a list of its parameters will appear on the screen.

If the file does not exist:
- The file is created in a plain text editor such as Notepad or Notepad ++.
- You need to set the robots name, extension .txt. Enter the data taking into account the accepted design standards.
- You can check for errors using services such as the Yandex webmaster. There, you need to select "Analysis robots.txt" in the "Tools" section and follow the prompts.
- When the file is ready, upload it to the root directory of the site.
Customization rules
Search engines have more than one robot. Some bots only index text content, some only graphical content. And the search engines themselves may have different crawlers' work patterns. This should be taken into account when compiling the file.
Some of them may ignore some of the rules, for example, GoogleBot does not respond to information about which mirror of the site should be considered the main one. But in general, they perceive and are guided by the file.
File syntax
Document parameters: the name of the robot (bot) “User-agent”, directives: allowing “Allow” and prohibiting “Disallow”.
Now there are two key search engines: Yandex and Google, respectively, it is important to take into account the requirements of both when creating a site.
The format for creating records is as follows, note the required spaces and blank lines.

User-agent directive
The robot searches for records that begin with User-agent, which should contain indications of the name of the search robot. If it is not specified, it is considered that the bots have unlimited access.
Disallow and Allow directives
If you need to disable indexing in robots.txt, use Disallow. With its help, they restrict the bot's access to the site or some sections.
If robots.txt does not contain any prohibiting directive "Disallow", it is considered that indexing of the entire site is allowed. Usually bans are written separately after each bot.
All information after the # sign is comments and cannot be read by the machine.
Allow is used to allow access.
The asterisk indicates that it applies to all: User-agent: *.
This option, on the contrary, means a complete prohibition of indexing for everyone.
Prevent viewing the entire contents of a specific directory folder
To block one file, you need to specify its absolute path
Sitemap, Host directives
For Yandex, it is customary to indicate which mirror you want to designate as the main one. And Google, as we remember, ignores it. If there are no mirrors, just record how you think it is correct to write your website name with or without www.
Clean-param directive
It can be used if the URLs of the website pages contain changeable parameters that do not affect their content (these can be user ids, referrers).
For example, in the address of the pages "ref" defines the traffic source, i.e. indicates where the visitor came from. The page will be the same for all users.
The robot can be instructed to do so, and it will not download duplicate information. This will reduce the load on the server.
Crawl-delay directive
With the help, you can determine how often the bot will load pages for analysis. This command is used when the server is overloaded and indicates that the crawl process needs to be accelerated.
Robots.txt errors
- The file is not in the root directory. Deeper the robot will not look for it and will not take it into account.
- The letters in the name must be small Latin.
A mistake in the name, sometimes they miss the letter S at the end and write robot. - You cannot use Cyrillic characters in your robots.txt file. If you need to specify a domain in Russian, use the format in the special Punycode encoding.
- It is a method of converting domain names to ASCII characters. To do this, you can use special converters.
This encoding looks like this:
site.рф \u003d xn - 80aswg.xn - p1ai
Additional information on what to close in robots txt and on the settings in accordance with the requirements of Google and Yandex search engines can be found in the reference documents. Different cms may also have their own characteristics, this should be taken into account.
Hello! Today I would like to tell you about robots.txt file... Yes, a lot has been written about him on the Internet, but to be honest, for a very long time I myself could not figure out how to create the correct robots.txt. In the end, I made one and it is on all my blogs. I don't notice any problems with it, robots.txt works just fine.
Robots.txt for WordPress
Why is robots.txt necessary? The answer is still the same -. That is, compiling robots.txt is one of the parts of a site's search engine optimization (by the way, very soon there will be a lesson that will be devoted to all the internal optimization of a WordPress site. So do not forget to subscribe to RSS so as not to miss interesting materials.).
One of the functions of this file is indexation prohibition unnecessary pages of the site. Also, the address is set in it and the main thing is written site mirror(site with www or without www).
Note: for search engines, the same site with www and without www is completely different sites. But, realizing that the content of these sites is the same, search engines "glue" them. Therefore, it is important to register the main site mirror in robots.txt. To find out which is the main thing (with www or without www), just type the address of your site in the browser, for example, with www, if you are automatically transferred to the same site without www, then the main mirror of your site is without www. Hopefully explained correctly.
So, this cherished, in my opinion, correct robots.txt for WordPress You can see below.
Proper Robots.txt for WordPress
User-agent: *
Disallow: / cgi-bin
Disallow: / wp-admin
Disallow: / wp-includes
Disallow: / wp-content / cache
Disallow: / wp-content / themes
Disallow: / trackback
Disallow: * / trackback
Disallow: * / * / trackback
Disallow: * / * / feed / * /
Disallow: * / feed
Disallow: / *? *
Disallow: / tag
User-agent: Yandex
Disallow: / cgi-bin
Disallow: / wp-admin
Disallow: / wp-includes
Disallow: / wp-content / plugins
Disallow: / wp-content / cache
Disallow: / wp-content / themes
Disallow: / trackback
Disallow: * / trackback
Disallow: * / * / trackback
Disallow: * / * / feed / * /
Disallow: * / feed
Disallow: / *? *
Disallow: / tag
Host: site
.gz
Sitemap: https: //site/sitemap.xml
All that is given above, you need to copy into a text document with the extension .txt, that is, so that the name of the file is robots.txt. You can create this text document, for example, using the program. Just don't forget, please change in the last three lines address to the address of your site. The robots.txt file must be located at the root of the blog, that is, in the same folder where the wp-content, wp-admin, etc. folders are located.
Those who are too lazy to create this text file, you can simply download robots.txt and also correct 3 lines there.
I want to note that in the technical parts, which will be discussed below, you do not need to overload yourself. I cite them for "knowledge", so to speak, a general outlook, so that they know what is needed and why.
So the line:
User-agent
sets the rules for a search engine: for example, “*” (asterisk) indicates that the rules are for all search engines, and what is below
User-agent: Yandex
means that these rules are for Yandex only.
Disallow
Here you "stick" the sections that do NOT need to be indexed by the search engines. For example, on the page https: // site / tag / seo, I have duplicate articles (repetition) with regular articles, and duplicate pages negatively affect search engine promotion, therefore, it is highly desirable that these sectors should be closed from indexing, which is what we we do with this rule:
Disallow: / tag
So, in the robots.txt that is given above, almost all unnecessary sections of the WordPress site are closed from indexing, that is, just leave everything as it is.
Host
Here we set the main mirror of the site, which I talked about just above.
Sitemap
In the last two lines, we set the URL for up to two sitemaps created with.
Possible problems
But because of this line in robots.txt, my site's posts are no longer indexed:
Disallow: / *? *
As you can see, this very line in robots.txt prohibits indexing articles, which of course we do not need at all. To fix this, you just need to remove these 2 lines (in the rules for all search engines and for Yandex) and the final correct robots.txt for a WordPress site without CNC will look like this:
User-agent: *
Disallow: / cgi-bin
Disallow: / wp-admin
Disallow: / wp-includes
Disallow: / wp-content / plugins
Disallow: / wp-content / cache
Disallow: / wp-content / themes
Disallow: / trackback
Disallow: * / trackback
Disallow: * / * / trackback
Disallow: * / * / feed / * /
Disallow: * / feed
Disallow: / tag
User-agent: Yandex
Disallow: / cgi-bin
Disallow: / wp-admin
Disallow: / wp-includes
Disallow: / wp-content / plugins
Disallow: / wp-content / cache
Disallow: / wp-content / themes
Disallow: / trackback
Disallow: * / trackback
Disallow: * / * / trackback
Disallow: * / * / feed / * /
Disallow: * / feed
Disallow: / tag
Host: site
Sitemap: https: //site/sitemap.xml
To check if we have compiled the robots.txt file correctly, I recommend that you use the Yandex Webmaster service (I told you how to register in this service).
We go to the section Indexing Settings -\u003e Robots.txt Analysis:
Already there, click on the "Download robots.txt from the site" button, and then click on the "Check" button:
If you see a message similar to the following, then you have the correct robots.txt for Yandex:

There are no trifles in SEO. Sometimes only one small file - Robots.txt can influence website promotion.If you want your site to go into the index so that search robots can crawl the pages you need, you need to write recommendations for them.
"Is it possible?", - you ask.Maybe. To do this, your site must have a robots.txt file.How to compose the file correctly robots, set up and add to the site - we understand this article.
What is robots.txt and what is it for?
Robots.txt is a plain text file, which contains recommendations for search robots: which pages should be crawled and which should not.
Important: the file must be encoded in UTF-8, otherwise search robots may not accept it.
Will a site go into the index without this file?It will come in, but robots can "snatch" those pages that are undesirable in the search results: for example, login pages, admin panel, personal pages of users, mirror sites, etc. All of this is considered "search junk":
If personal information is found in search results, both you and the site may suffer. One more thing - without this file, site indexing will take longer.
In the Robots.txt file, you can define three types of commands for search spiders:
- scanning is prohibited;
- scanning is allowed;
- scanning allowed partially.
All this is written using directives.
How to create the correct Robots.txt file for a website
The Robots.txt file can be created simply in Notepad, which is available on any computer by default. Registering the file will take even a beginner a maximum of half an hour (if you know the commands).
You can also use other programs - Notepad, for example. There are also online services that can generate a file automatically. For example, such asCY-PR.com or Mediasova.
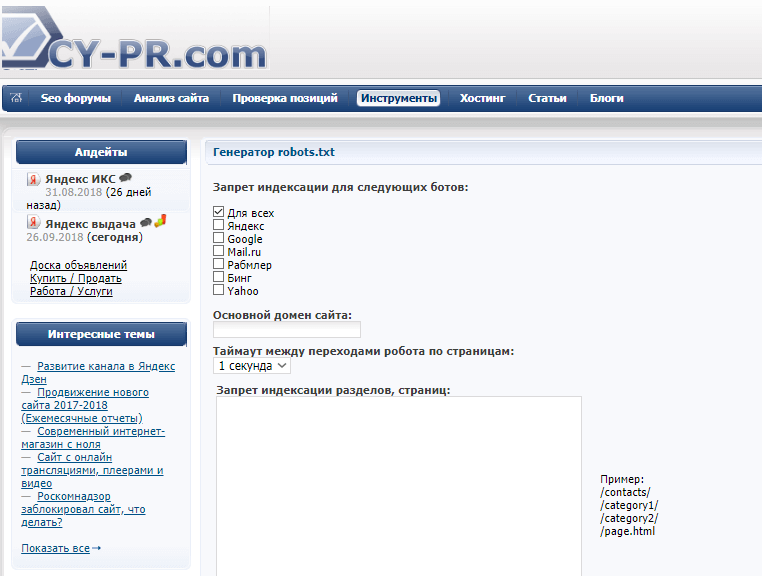
You just need to indicate the address of your site, for which search engines you need to set the rules, the main mirror (with or without www). Then the service will do everything itself.
Personally, I prefer the old "old-fashioned" way - to register the file manually in notepad. There is also a "lazy way" - to puzzle your developer with this 🙂 But even in this case, you should check if everything is spelled out correctly. Therefore, let's figure out how to compose this very file, and where it should be located.
The finished Robots.txt file should be located in the root folder of the site. Just a file, no folder:

Want to check if it is on your site? Type the address into the address bar: site.ru/robots.txt... This page will open for you (if the file exists):

The file consists of several indented blocks. Each block contains recommendations for search robots from different search engines (plus a block with general rules for everyone), and a separate block with links to a sitemap - Sitemap.
There is no need to indent inside a block with rules for one search robot.
Each block begins with a User-agent directive.
Each directive is followed by a ":" (colon), a space followed by a value (for example, which page to close from indexing).
You need to specify relative page addresses, not absolute ones. Relative is without “www.site.ru”. For example, you need to prevent the page from indexingwww.site.ru/shop... So after the colon we put a space, slash and "shop":
Disallow: / shop.
An asterisk (*) denotes any character set.
The dollar sign ($) is the end of the line.
You may decide - why write a file from scratch if you can open it on any site and just copy it to yourself?
For each site, you need to write unique rules. You need to consider the features CMS ... For example, the same admin panel is located at / wp-admin on the WordPress engine, but it will be different on a different one. The same is with the addresses of individual pages, with a sitemap and so on.
Customizing the Robots.txt file: indexing, main mirror, directives
As you have seen in the screenshot, the first is the User-agent directive. It indicates for which search robot the rules below will go.
User-agent: * - rules for all search robots, that is, any search engine (Google, Yandex, Bing, Rambler, etc.).
User-agent: Googlebot - indicates the rules for the Google search spider.
User-agent: Yandex - rules for the Yandex search robot.
For which search robot to write the rules first, there is no difference. But usually they write recommendations for all robots first.
Disallow: Disallow indexing
To prohibit indexing of the site as a whole or individual pages, the Disallow directive is used.
For example, you can completely close the site from indexing (if the resource is under construction and you do not want it to appear in the search results in this state). To do this, you need to register the following:
User-agent: *
Disallow: /
Thus, all search robots are prohibited from indexing content on the site.
And this is how you can open a site for indexing:
User-agent: *
Disallow:
Therefore, check if there is a slash after the Disallow directive if you want to close the site. If you want to open it later, do not forget to remove the rule (and this often happens).
To close individual pages from indexing, you need to specify their address. I already wrote how this is done:
User-agent: *
Disallow: / wp-admin
Thus, the administration panel was closed from outside views on the site.
What must be closed from indexing without fail:
- administrative panel;
- personal user pages;
- baskets;
- site search results;
- login, registration, authorization pages.
You can also close certain file types from indexing. Let's say you have some .pdf files on your site that you don't want to index. And search robots very easily scan the files uploaded to the site. You can close them from indexing as follows:
User-agent: *
Disallow: / *. pdf $
How to open a site for indexing
Even if the site is completely closed from indexing, it is possible for robots to open the path to certain files or pages. Let's say you are redesigning a site, but the service directory remains intact. You can direct the search bots there to continue indexing the section. For this, the Allow directive is used:
User-agent: *
Allow: / uslugi
Disallow: /
Main site mirror
Until March 20, 2018, in the robots.txt file for the Yandex search robot, it was necessary to specify the main site mirror through the Host directive. Now you don't need to do this - enough set up a pagination 301 redirect .
What is a master mirror? This is which address of your site is the main one - with or without www. If you do not configure a redirect, then both sites will be indexed, that is, there will be duplicates of all pages.
Sitemap: robots.txt sitemap
After all the directives for robots are registered, you need to specify the path to the Sitemap. The sitemap tells the robots that all the URLs that need to be indexed are at a specific address. For instance:
Sitemap: site.ru/sitemap.xml
When the robot crawls the site, it will see what changes were made to this file. As a result, new pages will be indexed faster.
Clean-param directive
In 2009 Yandex introduced a new directive - Clean-param. It can be used to describe dynamic parameters that do not affect the content of the pages. This directive is most often used on forums. There is a lot of garbage here, for example, session id, sorting parameters. If you specify this directive, the Yandex search robot will not repeatedly download information that is duplicated.
You can write this directive anywhere in the robots.txt file.
The parameters that the robot does not need to take into account are listed in the first part of the value through the & sign:
Clean-param: sid & sort /forum/viewforum.php
This directive avoids duplicate pages with dynamic URLs (which contain a question mark).
Crawl-delay directive
This directive will help those who have a weak server.
The arrival of a search robot is an additional load on the server. If you have a high traffic to the site, then the resource may simply not stand it and "lie down". As a result, the robot will receive a 5xx error message. If this situation is repeated constantly, the site may be recognized by the search engine as inoperative.
Imagine that you are working and at the same time you have to constantly answer calls. Your productivity then drops.
So it is with the server.
Let's go back to the directive. Crawl-delay allows you to set a delay in crawling site pages in order to reduce the load on the server. In other words, you set the period after which the site pages will be loaded. This parameter is indicated in seconds, an integer:
Hello dear readers of the Pingo SEO blog. In this article I want to outline my idea of \u200b\u200bhow to correctly compose robots.txt for a site. At one time I was very annoyed that the information on the Internet on this issue is rather sketchy. Because of this, I had to crawl through a large number of resources, constantly filtering repeating information and isolating new information.
Thus, here I will try to answer most of the questions, starting with the definition and ending with examples of real problems solved by this tool. If I forget something - write it down in the comments about it - I will research the issue and supplement the material.
Robots.txt - what is it, why is it needed and where does it live?
So, firstly, an educational program for those who are completely unfamiliar with this topic.
Robots.txt is a text file containing instructions for indexing a site for search engine robots. In this file, a webmaster can define the indexing parameters of his site both for all robots at once and for each search engine separately (for example, for Google).
Where is robots.txt located? It is located in the root folder of the FTP site, and, in fact, is a regular document in txt format, which can be edited using any text editor (I personally prefer Notepad ++). The contents of the robots file can be seen by entering http: //www.your-site.ru/robots.txt in the address bar of the browser. If, of course, it exists.
How to create a robots.txt for a website? It is enough to make a regular text file with this name and upload it to the site. How to properly configure and compose it will be discussed below.
Robots.txt file structure and configuration
What should the correct robots txt file look like for a site? The structure can be described as follows:
1. User-agent directive
What to write in this section? This directive determines which robot the following instructions are intended for. For example, if they are intended for all robots, then the following construction is sufficient:
In the syntax of a robots.txt file, "*" is equivalent to "anything." If you need to set instructions for a specific search engine or robot, then in place of the asterisk from the previous example, its name is written, for example:
User-agent: YandexBot
Each search engine has a whole set of robots that perform certain functions. Yandex search engine robots are described. In general terms, there is the following:
- Yandex - an indication of Yandex robots.
- GoogleBot is the main indexing robot.
- MSNBot is Bing's primary indexing robot.
- Aport - robots Aport.
- Mail.Ru - robots of PS Mail.
If there is a directive for a specific search engine or robot, then the general ones are ignored.
2. Allow directive
Allows individual pages of a section if, say, previously it was completely closed from indexing. For instance:
User-agent: *
Disallow: /
Allow: /open-page.html
In this example, we prohibit indexing the entire site, except for the poni.html page
This directive serves to some extent to indicate exceptions to the rules set by the Disallow directive. If there are no such situations, then the directive may not be used at all. It does not allow you to open the site for indexing, as many people think, because if there is no prohibition like Disallow: /, then it is open by default.
2. Disallow Directive
It is the antipode of the Allow directive and closes individual pages, sections or the entire site from indexing. Analogous to the noindex tag. For instance:
User-agent: *
Disallow: /closed-page.html
3. Host directive
Used only for Yandex and points to the main site mirror. It looks like this.
Primary mirror without www:
Main mirror from www:
Host: www.site.ru
Website on https:
Host: https://site.ru
You cannot write the host directive to the file twice. If, due to some error, this happened, then the directive that goes first is processed, and the second is ignored.
4. Sitemap directive
Used to specify the path to the XML sitemap.xml (if any). The syntax is as follows:
Sitemap: http://www.site.ru/sitemap.xml
5. Clean-param directive
It is used to close from indexing pages with parameters that can be duplicates. A very useful directive in my opinion, which cuts off the parametric tail of urls, leaving only the backbone, which is the original page address.
This problem is especially common when working with catalogs and online stores.
Let's say we have a page:
http://www.site.ru/index.php
And this page in the process of work can grow clones of the species.
http://www.site.ru/index.php?option\u003dcom_user_view\u003dremind
http://www.site.ru/index.php?option\u003dcom_user_view\u003dreset
http://www.site.ru/index.php?option\u003dcom_user_view\u003dlogin
In order to get rid of all possible variants of this spam, it is enough to specify the following construction:
Clean-param: option /index.php
The syntax from the example, I think, is clear:
Clean-param: # specify the directive
option # specify the spam parameter
/index.php # specify the url backbone with the spam parameter
If there are several parameters, then we simply list them through the ampersant (&):
http://www.site.ru/index.php?option\u003dcom_user_view\u003dremind&size\u003dbig # url with two parameters
Clean-param: option & big /index.php # specified two parameters separated by ampers
The example is taken simple, explaining the very essence. I would like to say especially thanks to this parameter when working with CMS Bitrix.
Crawl-Delay Directive
Allows you to set a timeout for loading site pages by the Yandex. It is used when the server is heavily loaded, in which it simply does not have time to quickly deliver content. In my opinion, this is an anachronism, which is no longer taken into account and which can be omitted.
Crawl-delay: 3.5 # 3.5 seconds timeout
Syntax
- # - used to write comments:
- * - means any sequence of characters, meaning:
- $ - rule truncation, anti-asterisk:
User-agent: * # directive applies to all robots
Disallow: / page * # disallow all pages starting with page
Disallow: / * page # Disallow all pages ending with page
Disallow: /cgi-bin/*.aspx # disallow all aspx pages in cgi-bin folder
Disallow: / page $ # only the page / page will be closed, not /page.html or pageline.html
Sample robots.txt file
In order to consolidate the understanding of the above structure and rules, we present the standard robots txt for the CMS Data Life Engine.
User-agent: * # directives are for all search engines
Disallow: /engine/go.php # disallow individual sections and pages
Disallow: /engine/download.php #
Disallow: / user / #
Disallow: / newposts / #
Disallow: / * subaction \u003d userinfo # close pages with separate parameters
Disallow: / * subaction \u003d newposts #
Disallow: / * do \u003d lastcomments #
Disallow: / * do \u003d feedback #
Disallow: / * do \u003d register #
Disallow: / * do \u003d lostpassword #
Host: www.site # specify the main mirror of the site
Sitemap: https: //site/sitemap.xml # specify the path to the sitemap
User-agent: Aport # specify the direction of the rules for the PS Aport
Disallow: / # suppose we don't want to be friends with them
Robots.txt check
How to check robots txt for correctness? The standard option is the Yandex validator - http://webmaster.yandex.ru/robots.xml. Enter the path to your robots file or immediately paste its contents into the text field. Enter the list of URLs that we want to check - they are closed or open according to the specified directives - click "Check" and voila! Profit.
The status of the page is displayed - whether it is open for indexing or closed. If closed, then it is indicated by which rule. To allow the indexing of such a page, you need to modify the rule pointed to by the validator. If there are syntax errors in the file, the validator will also report this.
Robots.txt generator - online creation
If you have no desire or time to study the syntax, but there is a need to close the spam pages of the site, then you can use any free online generator that will create a robots txt for the site with just a couple of clicks. Then you just have to download the file and upload it to your website. When working with it, you only need to check the boxes for the obvious settings, as well as indicate the pages that you want to close from indexing. The generator will do the rest for you.

Ready files for popular CMS
Robots.txt file for a site on 1C Bitrix
User-Agent: *
Disallow: / bitrix /
Disallow: / personal /
Disallow: / upload /
Disallow: / * login *
Disallow: / * auth *
Disallow: / * search
Disallow: / *? Sort \u003d
Disallow: / * gclid \u003d
Disallow: / * register \u003d
Disallow: / *? Per_count \u003d
Disallow: / * forgot_password \u003d
Disallow: / * change_password \u003d
Disallow: / * logout \u003d
Disallow: / * back_url_admin \u003d
Disallow: / * print \u003d
Disallow: / * backurl \u003d
Disallow: / * BACKURL \u003d
Disallow: / * back_url \u003d
Disallow: / * BACK_URL \u003d
Disallow: / * ADD2BASKET
Disallow: / * ADD_TO_COMPARE_LIST
Disallow: / * DELETE_FROM_COMPARE_LIST
Disallow: / * action \u003d BUY
Disallow: / * set_filter \u003d y
Disallow: / *? Mode \u003d matrix
Disallow: / *? Mode \u003d listitems
Disallow: / * openstat
Disallow: / * from \u003d adwords
Disallow: / * utm_source
Host: www.site.ru
Robots.txt for DataLife Engine (DLE)
User-agent: *
Disallow: /engine/go.php
Disallow: /engine/download.php
Disallow: / engine / classes / highslide /
Disallow: / user /
Disallow: / tags /
Disallow: / newposts /
Disallow: /statistics.html
Disallow: / * subaction \u003d userinfo
Disallow: / * subaction \u003d newposts
Disallow: / * do \u003d lastcomments
Disallow: / * do \u003d feedback
Disallow: / * do \u003d register
Disallow: / * do \u003d lostpassword
Disallow: / * do \u003d addnews
Disallow: / * do \u003d stats
Disallow: / * do \u003d pm
Disallow: / * do \u003d search
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt for Joomla
User-agent: *
Disallow: / administrator /
Disallow: / cache /
Disallow: / includes /
Disallow: / installation /
Disallow: / language /
Disallow: / libraries /
Disallow: / media /
Disallow: / modules /
Disallow: / plugins /
Disallow: / templates /
Disallow: / tmp /
Disallow: / xmlrpc /
Disallow: * print
Disallow: / * utm_source
Disallow: / * mailto *
Disallow: / * start *
Disallow: / * feed *
Disallow: / * search *
Disallow: / * users *
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt for Wordpress
User-agent: *
Disallow: / cgi-bin
Disallow: / wp-admin
Disallow: / wp-includes
Disallow: / wp-content / plugins
Disallow: / wp-content / cache
Disallow: / wp-content / themes
Disallow: * / trackback
Disallow: * / feed
Disallow: /wp-login.php
Disallow: /wp-register.php
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt for Ucoz
User-agent: *
Disallow: / a /
Disallow: / stat /
Disallow: / index / 1
Disallow: / index / 2
Disallow: / index / 3
Disallow: / index / 5
Disallow: / index / 7
Disallow: / index / 8
Disallow: / index / 9
Disallow: / panel /
Disallow: / admin /
Disallow: / secure /
Disallow: / informer /
Disallow: / mchat
Disallow: / search
Disallow: / shop / order /
Disallow: /? Ssid \u003d
Disallow: / google
Disallow: /
Robots.txt file - a text file in the .txt format that restricts search robots access to content on the http server. how definition, Robots.txt - this is robot exception standardwhich was adopted by the W3C consortium on January 30, 1994, and which is voluntarily used by most of the search engines. A robots.txt file consists of a set of instructions for crawlers to prevent certain files, pages, or directories from being indexed on a site. Consider the description of robots.txt for the case when the site does not restrict access to the site by robots.
Simple robots.txt example:
User-agent: * Allow: /
Here, the robots fully allows indexing of the entire site.
The robots.txt file must be uploaded to the root directory of your siteso that it is available at:
Your_site.ru / robots.txt
To place a robots.txt file at the site root usually requires FTP access.... However, some control systems (CMS) provide the ability to create robots.txt directly from the site control panel or through the built-in FTP manager.
If the file is available, you will see the contents of the robots.txt in your browser.
What is robots.txt for?
Roots.txt for the site is an important aspect. Why robots.txt is needed? For example, in SEO robots.txt is needed to exclude pages that do not contain useful content from indexing and much more... How, what, why and why it is excluded has already been described in the article about, we will not dwell on this here. Do you need a robots.txt file to all sites? Yes and no. If using robots.txt means excluding pages from search, then for small sites with a simple structure and static pages, such exclusions may be unnecessary. However, even for a small site, some robots.txt directives, for example the Host directive or Sitemap, but more on that below.
How to create robots.txt
Since robots.txt is a text file and that create a robots.txt file, you can use any text editor, for example Notepad... As soon as you opened a new text document, you have already started creating robots.txt, it remains only to compose its content, depending on your requirements, and save it as a text file called robots in txt format... It's simple, and creating a robots.txt file shouldn't be a problem even for beginners. I will show below how to compose robots.txt and what to write in a robot.
Create robots.txt online
Option for the lazy - create robots online and download robots.txt file already in finished form. Building robots txt online offers many services, the choice is yours. The main thing is to clearly understand what will be prohibited and what is allowed, otherwise creating a robots.txt file online can be a tragedywhich can be difficult to fix later. Especially if the search includes something that should have been closed. Be careful - check your robots file before uploading it to the site. Yet custom robots.txt file more accurately reflects the structure of restrictions than the one that was generated automatically and downloaded from another site. Read on to know what to look out for when editing robots.txt.
Editing robots.txt
Once you've managed to create your robots.txt file online or by hand, you can edit robots.txt... You can change its content as you like, the main thing is to follow some rules and robots.txt syntax. In the process of working on the site, the robots file may change, and if you are editing robots.txt, then do not forget to upload an updated, current version of the file with all the changes to the site. Next, let's look at the rules for configuring the file so that how to change robots.txt file and "don't chop wood."
Correct robots.txt setting
Correct robots.txt setting allows you to avoid getting private information in the search results of major search engines. However, do not forget that robots.txt commands are nothing more than a guide to action, not protection... Robots of reliable search engines like Yandex or Google follow robots.txt instructions, but other robots can easily ignore them. Correct understanding and application of robots.txt is the key to getting results.
To understand how to make correct robots txt, first you need to understand the general rules, syntax and directives of the robots.txt file.
Correct robots.txt starts with User-agent directive, which indicates to which robot specific directives are addressed.
Examples of User-agent in robots.txt:
# Specifies directives for all robots simultaneously User-agent: * # Specifies directives for all Yandex robots User-agent: Yandex # Specifies directives for only the main Yandex indexing robot User-agent: YandexBot # Specifies directives for all Google robots User-agent: Googlebot
Please note that such setting up a robots.txt file tells the robot to use only directives that match the user-agent with its name.
Example robots.txt with multiple User-agent occurrences:
# Will be used by all Yandex robots User-agent: Yandex Disallow: / * utm_ # Will be used by all Google robots User-agent: Googlebot Disallow: / * utm_ # Will be used by all robots except Yandex robots and Google User-agent: * Allow: / * utm_
User-agent directive creates only an indication to a specific robot, and immediately after the User-agent directive there should be a command or commands with a direct indication of the condition for the selected robot. In the example above, the "Disallow" directive is used, which has the value "/ * utm_". Thus, we close everything. Correct robots.txt setting prohibits empty line breaks between the directives "User-agent", "Disallow" and directives following "Disallow" within the current "User-agent".
An example of an incorrect line feed in robots.txt:
An example of a correct line break in robots.txt:
User-agent: Yandex Disallow: / * utm_ Allow: / * id \u003d User-agent: * Disallow: / * utm_ Allow: / * id \u003d
As you can see from the example, instructions in robots.txt come in blocks, each of which contains instructions either for a specific robot, or for all robots "*".
In addition, it is important to maintain proper order and sorting of commands in robots.txt when using directives such as "Disallow" and "Allow" together. The "Allow" directive is a permissive directive, which is the opposite of the "Disallow" robots.txt command - a prohibiting directive.
An example of sharing directives in robots.txt:
User-agent: * Allow: / blog / page Disallow: / blog
This example prohibits all robots from indexing all pages starting with “/ blog”, but allows indexing pages starting with “/ blog / page”.
Last example robots.txt in correct sort:
User-agent: * Disallow: / blog Allow: / blog / page
First, we prohibit the entire section, then we allow some of its parts.
Another correct example robots.txt with joint directives:
User-agent: * Allow: / Disallow: / blog Allow: / blog / page
Pay attention to the correct sequence of directives in this robots.txt.
The "Allow" and "Disallow" directives can be specified without parameters, in this case the value will be interpreted back to the "/" parameter.
An example of the "Disallow / Allow" directive without parameters:
User-agent: * Disallow: # equivalent to Allow: / Disallow: / blog Allow: / blog / page
How to write correct robots.txt and how to use the interpretation of directives is your choice. Both options will be correct. The main thing is not to get confused.
For the correct compilation of robots.txt, it is necessary to accurately indicate the priorities in the directive parameters and what will be prohibited from downloading by robots. We will consider more fully the use of the directives "Disallow" and "Allow" below, and now we will consider the syntax of robots.txt. Knowing the robots.txt syntax will bring you closer to create the perfect robots txt with your own hands.
Robots.txt syntax
Search engine robots voluntarily follow robots.txt commands - the standard for exceptions for robots, but not all search engines interpret the robots.txt syntax in the same way. The robots.txt file has a very specific syntax, but at the same time write robots txt not difficult, as its structure is very simple and easy to understand.
Here is a specific list of simple rules, following which you will eliminate frequent robots.txt errors:
- Each directive starts on a new line;
- Do not include more than one directive on one line;
- Don't put a space at the beginning of the line;
- The directive parameter must be on one line;
- You don't need to enclose directive parameters in quotes;
- Directive parameters do not require closing semicolons;
- The command in robots.txt is specified in the format - [Directive_name]: [optional space] [value] [optional space];
- Comments are allowed in robots.txt after the pound sign #;
- An empty line feed can be interpreted as the end of the User-agent directive;
- The directive "Disallow:" (with an empty value) is equivalent to "Allow: /" - allow everything;
- In directives "Allow", "Disallow" no more than one parameter is indicated;
- The name of the robots.txt file cannot be capitalized, the file name is misspelled - Robots.txt or ROBOTS.TXT;
- Capitalizing the names of directives and parameters is considered bad form and if by the standard robots.txt is case insensitive, it is often case sensitive to file and directory names;
- If the parameter of the directive is a directory, then a slash "/" is always placed before the name of the directory, for example: Disallow: / category
- Robots.txt that are too large (over 32 KB) are considered fully permissive, equivalent to "Disallow:";
- Robots.txt unavailable for any reason can be interpreted as fully permissive;
- If robots.txt is empty, then it will be treated as fully permissive;
- As a result of enumeration of several "User-agent" directives without an empty line feed, all subsequent "User-agent" directives, except for the first one, can be ignored;
- The use of any national alphabet characters in robots.txt is not allowed.
Since different search engines can interpret the robots.txt syntax in different ways, some points can be omitted. For example, if you write several “User-agent” directives without empty line feeds, all “User-agent” directives will be correctly interpreted by Yandex, since Yandex selects records by the presence of “User-agent” in the line.
In the robot, only what is needed should be strictly indicated, and nothing superfluous. Don't think how to register everything in robots txt, what is possible and how to fill it. Perfect robots txt Is the one with fewer lines but more meaning. "Brevity is the soul of wit". This expression comes in handy here.
How to check robots.txt
In order to check robots.txt for the correct syntax and file structure, you can use one of the online services. For example, Yandex and Google offer their own services for webmasters, which include robots.txt analysis:
Checking the robots.txt file in Yandex.Webmaster: http://webmaster.yandex.ru/robots.xml
In order to check robots.txt online necessary upload robots.txt to the site in the root directory... Otherwise, the service may report that failed to load robots.txt... It is recommended to pre-check robots.txt for availability at the address where the file is located, for example: your_site.ru / robots.txt.
In addition to verification services from Yandex and Google, there are many others online robots.txt validators.
Robots.txt vs Yandex and Google
There is a subjective opinion that the indication of a separate block of directives "User-agent: Yandex" in robots.txt Yandex perceives more positively than the general block of directives with "User-agent: *". A similar situation is robots.txt and Google. Specifying separate directives for Yandex and Google allows you to manage site indexing through robots.txt. Perhaps they are flattered by a personal appeal, especially since for most sites the content of the robots.txt blocks of Yandex, Google and other search engines will be the same. With rare exceptions, all User-agent blocks will have standard for robots.txt a set of directives. Also, using different "User-agent" you can install prohibiting indexing in robots.txt for Yandexbut not for Google, for example.
Separately, it should be noted that Yandex takes into account such an important directive as "Host", and the correct robots.txt for Yandex must include this directive to indicate the main mirror of the site. We will consider the "Host" directive in more detail below.
Disallow indexing: robots.txt Disallow
Disallow - prohibiting directivewhich is most commonly used in robots.txt. Disallow prohibits indexing of the site or part of it, depending on the path specified in the parameter of the Disallow directive.
An example of how to prevent indexing of a site in robots.txt:
User-agent: * Disallow: /
This example closes the entire site from indexing for all robots.
Special characters * and $ are allowed in the parameter of the Disallow directive:
* - any number of any characters, for example, the / page * parameter matches / page, / page1, / page-be-cool, / page / kak-skazat, etc. However, there is no need to include * at the end of each parameter, since, for example, the following directives are interpreted the same way:
User-agent: Yandex Disallow: / page User-agent: Yandex Disallow: / page *
$ - indicates the exact match of the exception to the parameter value:
User-agent: Googlebot Disallow: / page $
In this case, the Disallow directive will deny / page, but will not deny indexing of / page1, / page-be-cool, or / page / kak-skazat.
If close site indexing robots.txt, search engines may respond to this move with the error "Blocked in robots.txt" or "url restricted by robots.txt" (url prohibited by robots.txt). If you need disable page indexing, you can use not only robots txt, but also similar html tags:
- - do not index the content of the page;
- - do not follow the links on the page;
- - it is forbidden to index the content and follow the links on the page;
- - similar to content \u003d "none".
Allow Indexing: robots.txt Allow
Allow - allowing directive and the opposite of the Disallow directive. This directive has a syntax similar to Disallow.
An example of how to prevent indexing of a site in robots.txt except for some pages:
User-agent: * Disallow: / Allow: / page
It is forbidden to index the entire siteexcept for pages starting with / page.
Disallow and Allow with an empty parameter value
Empty Disallow directive:
User-agent: * Disallow:
Do not prohibit anything or allow indexing of the entire site and is equivalent to:
User-agent: * Allow: /
Empty Allow directive:
User-agent: * Allow:
Allow nothing or a complete prohibition of site indexing is equivalent to:
User-agent: * Disallow: /
Main site mirror: robots.txt Host
The Host directive is used to indicate to the Yandex robot the main mirror of your site... Of all the popular search engines, the directive Host is recognized only by Yandex robots... The Host directive is useful if your site is accessible by several, for example:
Mysite.ru mysite.com
Or to prioritize between:
Mysite.ru www.mysite.ru
You can tell the Yandex robot which mirror is the main one... The Host directive is specified in the "User-agent: Yandex" directive block and as a parameter, the preferred site address is indicated without "http: //".
An example robots.txt showing the main mirror:
User-agent: Yandex Disallow: / page Host: mysite.ru
The domain name mysite.ru without www is indicated as the main mirror. Thus, this type of address will be indicated in the search results.
User-agent: Yandex Disallow: / page Host: www.mysite.ru
The domain name www.mysite.ru is indicated as the main mirror.
Host directive in robots.txt file can be used only once, but if the Host directive is specified more than once, only the first will be taken into account, other Host directives will be ignored.
If you want to specify the main mirror for the Google crawler, use the Google Webmaster Tools service.
Sitemap: robots.txt sitemap
Using the Sitemap directive, in robots.txt, you can specify the location on the site.
An example robots.txt with a sitemap URL:
User-agent: * Disallow: / page Sitemap: http://www.mysite.ru/sitemap.xml
Specifying the sitemap address via sitemap directive in robots.txt allows the search robot to find out about the presence of a sitemap and start indexing it.
Clean-param directive
The Clean-param directive allows you to exclude pages with dynamic parameters from indexing. Similar pages can serve the same content with different page URLs. Simply put, it is as if the page is available at different addresses. Our task is to remove all unnecessary dynamic addresses, of which there may be a million. To do this, we exclude all dynamic parameters, using the Clean-param directive in robots.txt.
The syntax for the Clean-param directive is:
Clean-param: parm1 [& parm2 & parm3 & parm4 & .. & parmn] [Path]
Consider a page with the following URL as an example:
Www.mysite.ru/page.html?&parm1\u003d1&parm2\u003d2&parm3\u003d3
Robots.txt Clean-param example:
Clean-param: parm1 & parm2 & parm3 /page.html # for page.html only
Clean-param: parm1 & parm2 & parm3 / # for everyone
Crawl-delay directive
This instruction allows you to reduce the load on the server if robots visit your site too often. This directive is relevant mainly for sites with a large volume of pages.
Example robots.txt Crawl-delay:
User-agent: Yandex Disallow: / page Crawl-delay: 3
In this case, we “ask” the Yandex robots to download the pages of our site no more often than once every three seconds. Some search engines support fractional format as a parameter crawl-delay robots.txt directives.