Sort data in Excel by rows and columns using formulas. How the testing was done. Sort by cell color and font
Almost all more or less active users of this program know that tables can be created in the Microsoft Word word processor. Yes, everything here is not as professionally implemented as in Excel, but for everyday needs, the capabilities of a text editor are more than enough. We have already written quite a lot about the features of working with tables in Word, and in this article we will consider one more topic.
How do I sort a table alphabetically? Most likely, this is not the most popular question among users of Microsoft's brainchild, but not everyone knows the answer to it. In this article, we'll show you how to sort the contents of a table alphabetically, as well as how to sort in a separate column.
1. Select a table with all its contents: to do this, place the cursor in its upper left corner, wait for the table moving sign to appear (- a small cross located in a square) and click on it.

2. Go to the tab "Layout"(section "Working with tables") and press the button "Sorting"located in the group "Data".

Note: Before proceeding to sort the data in the table, we recommend cutting or copying to another place the information contained in the header (first line). This will not only make sorting easier, but will also keep the table header in its place. If the position of the first row of the table is not important for you, and it should also be sorted alphabetically, select it too. Alternatively, you can simply select a table without a header.
3. Select the required data sorting parameters in the window that opens.

If you need the data to be sorted relative to the first column, in the sections "Sort by", "Then by", "Then by" set "Columns 1".

If each column of the table must be sorted alphabetically, regardless of the other columns, you need to do this:
- "Sort by" - "Columns 1";
- "Then by" - "Columns 2";
- "Then by" - "Columns 3".
Note:In our example, we are only alphabetically sorting the first column.
In the case of text data, as in our example, the parameters "A type" and "By" for each line should be left unchanged ( "Text" and "Paragraphs", respectively). Actually, it is simply impossible to sort numerical data alphabetically.

The last column in the window " Sorting" is responsible, in fact, for the sorting type:
- "Ascending" - in alphabetical order (from "A" to "Z");
- "Descending" - in reverse alphabetical order (from "I" to "A").

4. After setting the required values, click "OK"to close the window and see the changes.

5. The data in the table will be sorted alphabetically.
Don't forget to put the hat back in place. Click in the first cell of the table and click "CTRL + V" or button "Paste" in a group "Clipboard" (tab "Home").

Sort a single column of a table alphabetically
Sometimes it becomes necessary to sort in alphabetical order the data from only one column of the table. Moreover, this must be done so that the information from all other columns remains in its place. If it only concerns the first column, you can use the above method, doing it in the same way as we did in our example. If this is not the first column, follow these steps:
1. Select the table column that you want to sort alphabetically.

2. In the tab "Layout" in the tool group "Data" press the button "Sorting".

3. In the window that opens, in the section "First by" select an initial sorting option:
- data of a specific cell (in our example, this is the letter "B");
- specify the ordinal number of the selected column;
- repeat the same action for the "Then by" sections.

Note:Which type of sorting to choose (parameters "Sort by" and "Then by") depends on the data in the column cells. In our example, when only letters are indicated in the cells of the second column for alphabetical sorting, it is enough simply to specify in all sections "Columns 2"... In this case, there is no need to perform the manipulations described below.
4. At the bottom of the window, set the parameter switch "List" to the required position:
- "Title line";
- "No title bar".

Note: The first parameter "pulls" the header to sorting, the second - allows you to sort the column without taking into account the header.
5. Press the button below "Parameters".
6. In the section Sorting options check the box next to Columns only.

7. Closing the window Sorting options ("OK" button), make sure that the marker is set next to all sorting type items "Ascending" (alphabetical order) or "Descending" (reverse alphabetical order).

8. Close the window by clicking "OK".

The column you selected will be sorted alphabetically.
That's all, now you know how to sort the Word table alphabetically.
Let's create an array, which will contain the answer after the completion of the algorithm. We will alternately insert elements from the original array so that the elements in the response array are always sorted. The asymptotics in the mean and worst case is O (n 2), in the best case it is O (n). It is more convenient to implement the algorithm in a different way (creating a new array and actually inserting something into it is relatively difficult): we just make it so that some prefix of the original array is sorted, instead of inserting, we will change the current element with the previous one, while they are in the wrong order.Implementation:
void insertionsort (int * l, int * r) (for (int * i \u003d l + 1; i< r; i++) { int* j = i; while (j > l && * (j - 1)\u003e * j) (swap (* (j - 1), * j); j--;)))
Shellsort
Let's use the same idea as comb sorting and apply to insert sort. Let's fix some distance. Then the elements of the array will be divided into classes - elements, the distance between which is a multiple of the fixed distance, fall into one class. Let's sort each class by insertion sort. Unlike sorting with a comb, the optimal set of distances is unknown. There are quite a few sequences with different ratings. Shell sequence - the first element is equal to the length of the array, each next one is half the size of the previous one. The worst case asymptotics is O (n 2). The Hibbard sequence is 2 n - 1, the asymptotics in the worst case is O (n 1,5), the Sedgwick sequence (the formula is nontrivial, you can see it at the link below) - O (n 4/3), Pratt (all products of powers of two and triplets) - O (nlog 2 n). Note that all these sequences need to be calculated only up to the size of the array and run from the largest to the smallest (otherwise, you just get sorting by insertions). I also did additional research and tested different sequences of the form s i \u003d a * s i - 1 + k * s i - 1 (in part this was inspired by the empirical Tsiur sequence - one of the best sequences of distances for a small number of elements). The best were the sequences with the coefficients a \u003d 3, k \u003d 1/3; a \u003d 4, k \u003d 1/4 and a \u003d 4, k \u003d -1/5.Several useful links:
Implementations:
void shellsort (int * l, int * r) (int sz \u003d r - l; int step \u003d sz / 2; while (step\u003e< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)) step / \u003d 2; )) void shellsorthib (int * l, int * r) (int sz \u003d r - l; if (sz<= 1) return; int step = 1; while (step < sz) step <<= 1; step >\u003e \u003d 1; step--; while (step\u003e \u003d 1) (for (int * i \u003d l + step; i< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)) step / \u003d 2; )) int steps; void shellsortsedgwick (int * l, int * r) (int sz \u003d r - l; steps \u003d 1; int q \u003d 1; while (steps * 3< sz) { if (q % 2 == 0) steps[q] = 9 * (1 << q) - 9 * (1 << (q / 2)) + 1; else steps[q] = 8 * (1 << q) - 6 * (1 << ((q + 1) / 2)) + 1; q++; } q--; for (; q > < r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)))) void shellsortpratt (int * l, int * r) (int sz \u003d r - l; steps \u003d 1; int cur \u003d 1, q \u003d 1; for (int i \u003d 1; i< sz; i++) { int cur = 1 << i; if (cur > sz / 2) break; for (int j \u003d 1; j< sz; j++) { cur *= 3; if (cur > sz / 2) break; steps \u003d cur; )) insertionsort (steps, steps + q); q--; for (; q\u003e \u003d 0; q--) (int step \u003d steps [q]; for (int * i \u003d l + step; i< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)))) void myshell1 (int * l, int * r) (int sz \u003d r - l, q \u003d 1; steps \u003d 1; while (steps< sz) { int s = steps; steps = s * 4 + s / 4; } q--; for (; q >\u003d 0; q--) (int step \u003d steps [q]; for (int * i \u003d l + step; i< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)))) void myshell2 (int * l, int * r) (int sz \u003d r - l, q \u003d 1; steps \u003d 1; while (steps< sz) { int s = steps; steps = s * 3 + s / 3; } q--; for (; q >\u003d 0; q--) (int step \u003d steps [q]; for (int * i \u003d l + step; i< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;)))) void myshell3 (int * l, int * r) (int sz \u003d r - l, q \u003d 1; steps \u003d 1; while (steps< sz) { int s = steps; steps = s * 4 - s / 5; } q--; for (; q >\u003d 0; q--) (int step \u003d steps [q]; for (int * i \u003d l + step; i< r; i++) { int *j = i; int *diff = j - step; while (diff >\u003d l && * diff\u003e * j) (swap (* diff, * j); j \u003d diff; diff \u003d j - step;))))
Tree sort
We will insert elements into a binary search tree. After all the elements are inserted, it is enough to traverse the tree in depth and get a sorted array. If you use a balanced tree such as red-black, the asymptotics will be O (nlogn) at worst, average, and best. The implementation uses the multiset container.Implementation:
void treesort (int * l, int * r) (multiset
Gnome sort
The algorithm is similar to insertion sort. We maintain the pointer to the current element, if it is larger than the previous one or if it is the first - we shift the pointer one position to the right, otherwise we change the current and previous elements in places and shift to the left.Implementation:
void gnomesort (int * l, int * r) (int * i \u003d l; while (i< r) { if (i == l || *(i - 1) <= *i) i++; else swap(*(i - 1), *i), i--; } }
Selection sort
At the next iteration, we will find the minimum in the array after the current element and change it with it, if necessary. Thus, after the i-th iteration, the first i elements will stay in their places. Asymptotics: O (n 2) best, average and worst case. It should be noted that this sorting can be implemented in two ways - keeping the minimum and its index, or simply rearranging the current element with the considered one, if they are in the wrong order. The first method turned out to be a little faster, so it was implemented.Implementation:
void selectionsort (int * l, int * r) (for (int * i \u003d l; i< r; i++) { int minz = *i, *ind = i; for (int *j = i + 1; j < r; j++) { if (*j < minz) minz = *j, ind = j; } swap(*i, *ind); } }
Heapsort / Heapsort
Development of the idea of \u200b\u200bsorting by choice. Let's use the "heap" data structure (or "pyramid", hence the name of the algorithm). It allows you to get the minimum in O (1), adding elements and extracting the minimum in O (logn). So the asymptotics are O (nlogn) at worst, mean and best. I implemented the heap myself, although in C ++ there is a priority_queue container, since this container is quite slow.Implementation:
template
Quicksort / Quicksort
Let's choose some pivot element. After that, let's move all the elements smaller than him to the left, and large ones to the right. Let's recursively call from each of the parts. As a result, we get a sorted array, since each element less than the pivot was before each larger pivot. Asymptotics: O (nlogn) mean and best, O (n 2). The worst estimate is achieved with an unsuccessful choice of the support element. My implementation of this algorithm is completely standard, we go simultaneously from the left and right, find a couple of elements, such that the left element is larger than the pivot element, and the right one is smaller, and swap them. In addition to pure quick sort, sorting was also involved in the comparison, switching to insertion sort with a small number of elements. The constant was matched by testing, and insertion sort is the best sort for this task (although you shouldn't think that it is the fastest of the quadratic ones).Implementation:
void quicksort (int * l, int * r) (if (r - l<= 1) return; int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll<= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quicksort(l, rr + 1); if (ll < r) quicksort(ll, r); } void quickinssort(int* l, int* r) { if (r - l <= 32) { insertionsort(l, r); return; } int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll<= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quickinssort(l, rr + 1); if (ll < r) quickinssort(ll, r); }
Merge sort
Divide and Conquer paradigm sorting. Divide the array in half, recursively sort the parts, and then perform the merge procedure: we maintain two pointers, one to the current element of the first part, the second to the current element of the second part. From these two elements we select the minimum, insert it into the answer and shift the pointer corresponding to the minimum. Merging works in O (n), only logn levels, so the asymptotics is O (nlogn). It is efficient to pre-create a temporary array and pass it as an argument to the function. This sorting is recursive, like fast sorting, and therefore it is possible to switch to a quadratic one with a small number of elements.Implementation:
void merge (int * l, int * m, int * r, int * temp) (int * cl \u003d l, * cr \u003d m, cur \u003d 0; while (cl< m && cr < r) { if (*cl < *cr) temp = *cl, cl++; else temp = *cr, cr++; } while (cl < m) temp = *cl, cl++; while (cr < r) temp = *cr, cr++; cur = 0; for (int* i = l; i < r; i++) *i = temp; } void _mergesort(int* l, int* r, int* temp) { if (r - l <= 1) return; int *m = l + (r - l) / 2; _mergesort(l, m, temp); _mergesort(m, r, temp); merge(l, m, r, temp); } void mergesort(int* l, int* r) { int* temp = new int; _mergesort(l, r, temp); delete temp; } void _mergeinssort(int* l, int* r, int* temp) { if (r - l <= 32) { insertionsort(l, r); return; } int *m = l + (r - l) / 2; _mergeinssort(l, m, temp); _mergeinssort(m, r, temp); merge(l, m, r, temp); } void mergeinssort(int* l, int* r) { int* temp = new int; _mergeinssort(l, r, temp); delete temp; }
Counting sort
Let's create an array of size r - l, where l is the minimum and r is the maximum element of the array. After that, let's go through the array and count the number of occurrences of each element. Now you can go through the array of values \u200b\u200band write out each number as many times as needed. The asymptotics is O (n + r - l). You can modify this algorithm to make it stable: for this we determine the place where the next number should be (these are just prefix sums in the array of values) and we will go through the original array from left to right, putting the element in the correct place and increasing the position by 1. This sorting was not tested because most of the tests contained numbers large enough not to create an array of the required size. However, it nevertheless came in handy.Bucket sort
(also known as basket and pocket sort). Let l be the minimum and r the maximum element of the array. Let's split the elements into blocks, the first will contain elements from l to l + k, in the second - from l + k to l + 2k, etc., where k \u003d (r - l) / the number of blocks. In general, if the number of blocks is two, then this algorithm turns into a kind of quick sort. The asymptotics of this algorithm is unclear, the running time depends on both the input data and the number of blocks. It is argued that the run time is linear on good data. The implementation of this algorithm turned out to be one of the most difficult tasks. You can do it like this: just create new arrays, recursively sort and glue them. However, this approach is still rather slow and did not suit me. There are several ideas used in effective implementation:1) We will not create new arrays. To do this, we will use the technique of sorting by counting - we will count the number of elements in each block, prefix sums and, thus, the position of each element in the array.
2) We will not start from empty blocks. Let's put the indices of non-empty blocks into a separate array and start only from them.
3) Check if the array is sorted. This will not worsen the running time, since you still need to make a pass in order to find the minimum and maximum, however, it will allow the algorithm to speed up on partially sorted data, because the elements are inserted into new blocks in the same order as in the original array.
4) Since the algorithm turned out to be rather cumbersome, with a small number of elements, it is extremely ineffective. To such an extent that switching to insertion sort speeds up the work by about 10 times.
It remains only to understand how many blocks you need to select. On randomized tests, I was able to get the following estimate: 1500 blocks for 10 7 elements and 3000 for 10 8. It was not possible to find a formula - the operating time deteriorated several times.
Implementation:
void _newbucketsort (int * l, int * r, int * temp) (if (r - l<= 64) { insertionsort(l, r); return; } int minz = *l, maxz = *l; bool is_sorted = true; for (int *i = l + 1; i < r; i++) { minz = min(minz, *i); maxz = max(maxz, *i); if (*i < *(i - 1)) is_sorted = false; } if (is_sorted) return; int diff = maxz - minz + 1; int numbuckets; if (r - l <= 1e7) numbuckets = 1500; else numbuckets = 3000; int range = (diff + numbuckets - 1) / numbuckets; int* cnt = new int; for (int i = 0; i <= numbuckets; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; int ind = (*i - minz) / range; cnt++; } int sz = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= numbuckets; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = (temp - minz) / range; *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _newbucketsort(l + cnt, l + cnt[r], temp); else _newbucketsort(l, l + cnt[r], temp); } delete run; delete cnt; } void newbucketsort(int* l, int* r) { int *temp = new int; _newbucketsort(l, r, temp); delete temp; }
Radix sort
(also known as digital sort). There are two versions of this sorting, in which, in my opinion, there is little in common, except for the idea of \u200b\u200busing the representation of a number in some number system (for example, binary).LSD (least significant digit):
Let's represent each number in binary. At each step of the algorithm, we will sort the numbers in such a way that they are sorted by the first k * i bits, where k is some constant. From this definition it follows that at each step it is sufficiently stable to sort the elements by new k bits. Sorting by counting is ideal for this (you need 2 k memory and time, which is not much with a good choice of the constant). Asymptotics: O (n), assuming that the numbers are of a fixed size (otherwise it would not be possible to assume that the comparison of two numbers is performed in a unit of time). The implementation is pretty straightforward.Implementation:
int digit (int n, int k, int N, int M) (return (n \u003e\u003e (N * k) & (M - 1));) void _radixsort (int * l, int * r, int N) ( int k \u003d (32 + N - 1) / N; int M \u003d 1<< N; int sz = r - l; int* b = new int; int* c = new int[M]; for (int i = 0; i < k; i++) { for (int j = 0; j < M; j++) c[j] = 0; for (int* j = l; j < r; j++) c++; for (int j = 1; j < M; j++) c[j] += c; for (int* j = r - 1; j >\u003d l; j--) b [- c] \u003d * j; int cur \u003d 0; for (int * j \u003d l; j< r; j++) *j = b; } delete b; delete c; } void radixsort(int* l, int* r) { _radixsort(l, r, 8); }
MSD (most significant digit):
Actually, some kind of block sort. One block will contain numbers with equal k bits. The asymptotics is the same as for the LSD version. The implementation is very similar to block sort, but simpler. It uses the digit function defined in the LSD version implementation.Implementation:
void _radixsortmsd (int * l, int * r, int N, int d, int * temp) (if (d \u003d\u003d -1) return; if (r - l<= 32) { insertionsort(l, r); return; } int M = 1 << N; int* cnt = new int; for (int i = 0; i <= M; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; cnt++; } int sz = 0; for (int i = 1; i <= M; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= M; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= M; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = digit(temp, d, N, M); *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _radixsortmsd(l + cnt, l + cnt[r], N, d - 1, temp); else _radixsortmsd(l, l + cnt[r], N, d - 1, temp); } delete run; delete cnt; } void radixsortmsd(int* l, int* r) { int* temp = new int; _radixsortmsd(l, r, 8, 3, temp); delete temp; }
Bitonic sort:
The idea behind this algorithm is that the original array is converted into a biton sequence - a sequence that first increases and then decreases. It can be effectively sorted as follows: split the array into two parts, create two arrays, add to the first all the elements equal to the minimum of the corresponding elements of each of the two parts, and to the second - equal to the maximum. It is argued that there will be two bitonic sequences, each of which can be recursively sorted in the same way, after which you can glue the two arrays (since any element of the first is less than or equal to any element of the second). In order to convert the original array into a biton sequence, we will do the following: if the array consists of two elements, you can simply end, otherwise divide the array in half, recursively call the algorithm from the halves, then sort the first part in order, the second in reverse order and glue ... Obviously, you get a biton sequence. Asymptotics: O (nlog 2 n), because when constructing the biton sequence, we used sorting that works in O (nlogn), and there were logn levels in total. Also note that the size of the array must be a power of two, so you may have to supplement it with dummy elements (which does not affect the asymptotics).Implementation:
void bitseqsort (int * l, int * r, bool inv) (if (r - l<= 1) return; int *m = l + (r - l) / 2; for (int *i = l, *j = m; i < m && j < r; i++, j++) { if (inv ^ (*i > * j)) swap (* i, * j); ) bitseqsort (l, m, inv); bitseqsort (m, r, inv); ) void makebitonic (int * l, int * r) (if (r - l<= 1) return; int *m = l + (r - l) / 2; makebitonic(l, m); bitseqsort(l, m, 0); makebitonic(m, r); bitseqsort(m, r, 1); } void bitonicsort(int* l, int* r) { int n = 1; int inf = *max_element(l, r) + 1; while (n < r - l) n *= 2; int* a = new int[n]; int cur = 0; for (int *i = l; i < r; i++) a = *i; while (cur < n) a = inf; makebitonic(a, a + n); bitseqsort(a, a + n, 0); cur = 0; for (int *i = l; i < r; i++) *i = a; delete a; }
Timsort
A hybrid sort that combines insertion sort and merge sort. Let's split the array elements into several subarrays of a small size, while expanding the subarray while the elements in it are sorted. Let's sort the subarrays by insertion sort, taking advantage of the fact that it works effectively on sorted arrays. Next, we will merge subarrays as in merge sort, taking them of approximately equal size (otherwise, the running time will approach the quadratic). For this, it is convenient to store subarrays in the stack, maintaining the invariant - the farther from the top, the larger the size, and merge subarrays at the top only when the size of the third subarray farthest from the top is greater or equal to the sum of their sizes. Asymptotics: O (n) at best and O (nlogn) at average and worst. The implementation is non-trivial, I have no firm confidence in it, but the running time it showed quite good and consistent with my ideas about how this sort should work.More details about timsort are described here:
Implementation:
void _timsort (int * l, int * r, int * temp) (int sz \u003d r - l; if (sz<= 64) {
insertionsort(l, r);
return;
}
int minrun = sz, f = 0;
while (minrun >\u003d 64) (f | \u003d minrun & 1; minrun \u003e\u003e \u003d 1;) minrun + \u003d f; int * cur \u003d l; stack
Testing
Iron and system
Processor: Intel Core i7-3770 CPU 3.40 GHzRAM: 8 GB
Testing was conducted on a near-clean Windows 10 x64 system installed several days prior to launch. The IDE used is Microsoft Visual Studio 2015.
Tests
All tests are divided into four groups. The first group is an array of random numbers in different modules (10, 1000, 10 5, 10 7 and 10 9). The second group is an array that is split into several sorted subarrays. In fact, an array of random numbers was taken modulo 10 9, and then subarrays of size equal to the minimum of the length of the remaining suffix and a random number modulo some constant were sorted. A sequence of constants - 10, 100, 1000, etc. up to the size of the array. The third group is an initially sorted array of random numbers with a certain number of "swaps" - permutations of two random elements. The sequence of swap amounts is the same as in the previous group. Finally, the last group consists of several tests with a fully sorted array (in forward and reverse order), several tests with an initial array of natural numbers from 1 to n, in which several numbers are replaced by a random one, and tests with a large number of repetitions of one element (10 %, 25%, 50%, 75% and 90%). Thus, tests allow us to see how sorts work on random and partially sorted arrays, which looks the most significant. The fourth group is in many ways directed against linear-time sorts, which like sequences of random numbers. At the end of the article, there is a link to a file that details all tests.Input data size
It would be rather silly to compare, for example, linear and quadratic sorting, and run them on tests of the same size. Therefore, each of the test groups is divided into four more groups, size 10 5, 10 6, 10 7 and 10 8 elements. The sorts were divided into three groups, in the first - quadratic (bubble, insertion, selection, shaker and gnome sort), in the second - something between logarithmic time and square, (biton, several types of Shell sort and tree sort), in the third all rest. It may surprise someone that tree sorting is not in the third group, although its asymptotics is O (nlogn), but, unfortunately, its constant is very large. The sorts of the first group were tested on tests with 10 5 elements, the second group - on tests with 10 6 and 10 7, the third - on tests with 10 7 and 10 8. It is these data sizes that allow you to somehow see an increase in the operating time, with smaller sizes the error is too large, with large data the algorithm works too long (or lack of RAM). With the first group, I did not bother so as not to break the tenfold increase (10 4 elements for quadratic sorts are too small), after all, they are of little interest in themselves.How was testing done
On each test, 20 runs were made, the total runtime was the average of the resulting values. Almost all the results were obtained after one run of the program, however, due to several errors in the code and system glitches (nevertheless, testing lasted almost a week of clean time), some sorts and tests had to be re-tested later.Implementation subtleties
Perhaps it will surprise someone that in the implementation of the testing process itself, I did not use function pointers, which would greatly reduce the code. It turned out that this significantly slows down the algorithm (by about 5-10%). Therefore, I used a separate call to each function (this, of course, would not affect the relative speed, but ... I still want to improve the absolute one). For the same reason, vectors were replaced by ordinary arrays, templates and comparator functions were not used. All this is more relevant for industrial use of the algorithm than for testing it.results
All results are available in several forms - three diagrams (a histogram, which shows the change in speed when moving to the next limitation on one type of tests, a graph showing the same, but sometimes more clearly, and a histogram, which shows which sort is best runs on some type of tests) and the tables they are based on. The third group was divided into three more parts, otherwise little would have been clear. However, and so far not all diagrams are successful (I strongly doubt the usefulness of the third type of diagrams), but I hope everyone can find the most suitable one for understanding.Since there are a lot of pictures, they are hidden by spoilers. A few comments on the notation. The sorts are named as above, if this is a Shell sort, then the author of the sequence is indicated in parentheses, Ins is assigned to the names of sorts that switch to sorting by insertions (for compactness). In the diagrams, the second group of tests indicates the possible length of sorted subarrays, the third group - the number of swaps, and the fourth - the number of replacements. The overall result was calculated as the average of the four groups.
First group of sorts
Array of random numbers
Tables



Quite boring results, even partial sorting with a small module is almost invisible.
Tables




Much more interesting. The exchange sortings reacted most violently, the shaker even overtook the dwarf. Insertion sort only sped up towards the end. Selection sort, of course, works exactly the same.
Swaps
Tables





Here, at last, sorting by inserts has shown itself, although the speed increase for the shaker is about the same. This is where the weakness of bubble sort is revealed - one swap is enough to move a small element to the end, and it already works slowly. The selection sort was almost at the end.
Permutation changes
Tables





The group is almost no different from the previous one, so the results are similar. However, bubble sort breaks ahead, since the random element inserted into the array will most likely be larger than the others, that is, it will move to the end in one iteration. Selection sorting has become an outsider.
Replays
Tables





Here, all sorts (except, of course, selection sort) worked almost the same, speeding up as the number of repetitions increased.
Final results

Due to its absolute indifference to the array, selection sort, which worked the fastest on random data, still lost to insertion sort. Dwarven sorting turned out to be noticeably worse than the latter, which is why its practical application is questionable. Shaker and bubble grades were the slowest.
Second group of sorts
Array of random numbers
Tables, 1e6 elements




Shell's sorting with Pratt's sequence behaves very strange, the rest is more or less clear. Tree sort loves partially sorted arrays, but does not like repetitions, which is probably why the worst running time is in the middle.
Tables, 1e7 elements




Everything is as before, only Shell and Pratt strengthened in the second group due to the sorting. The influence of the asymptotics also becomes noticeable - sorting by a tree is in second place, in contrast to a group with a smaller number of elements.
Partially sorted array
Tables, 1e6 elements




Here all sortings behave in an understandable way, except for Shell and Hibbard, who for some reason does not immediately begin to accelerate.
Tables, 1e7 elements




Everything is here, in general, as before. Even the asymptotics of tree sorting did not help her get out of the last place.
Swaps
Tables, 1e6 elements





Tables, 1e7 elements




It is noticeable here that Shell's sortings are highly dependent on partial sortedness, since they behave almost linearly, and the other two only fall strongly on the latter groups.
Permutation changes
Tables, 1e6 elements




Tables, 1e7 elements




Everything here is similar to the previous group.
Replays
Tables, 1e6 elements




Again, all the sorts have demonstrated amazing balance, even bitonic ones, which, it would seem, are almost independent of the array.
Tables, 1e7 elements




Nothing interesting.
Final results


A convincing first place was taken by Shell's sort by Hibbard, not losing in any intermediate group. Perhaps it was worth sending her to the first sorting group, but ... she is too weak for that, and even then there would be almost no one in the group. Biton sort took the second place quite confidently. The third place with a million elements was taken by another Shell sort, and with ten million the tree sort (the asymptotic behavior affected). It is worth noting that with a tenfold increase in the size of the input data, all algorithms, except for tree sorting, slowed down by almost 20 times, and the latter only by 13.
Third group of sorting
Array of random numbers
Tables, 1e7 elements











Tables, 1e8 elements











Almost all sortings in this group have almost the same dynamics. Why is it that almost all sorts are speeded up when the array is partially sorted? Exchange sorts work faster because fewer exchanges have to be done, in Shell sort, insertion sort is performed, which is greatly accelerated on such arrays, in heapsort, when elements are inserted, the sifting ends immediately, in merge sort, half as many comparisons are performed at best. The smaller the difference between the minimum and maximum elements, the better the block sort works. Only radix sorting is fundamentally different, which does not care about all this. The LSD version works better the larger the module. The dynamics of the MSD version is not clear to me, the fact that it worked faster than LSD surprised me.
Partially sorted array
Tables, 1e7 elements











Tables, 1e8 elements











Everything is pretty clear here too. The Timsort algorithm has become noticeable, the sorting affects it more than the others. This allowed this algorithm to nearly equal the optimized version of quicksort. Block sort, despite the improvement in runtime with partial sorting, could not outperform radix sort.
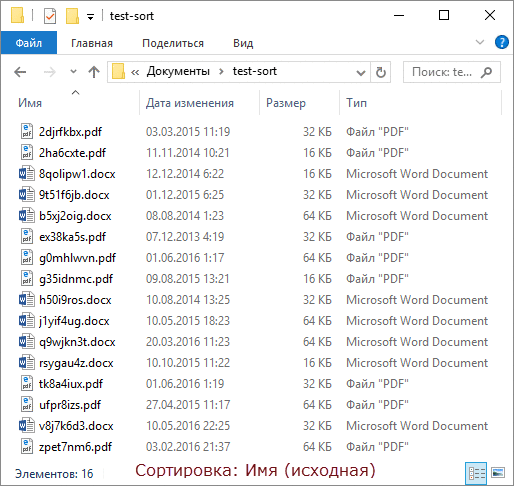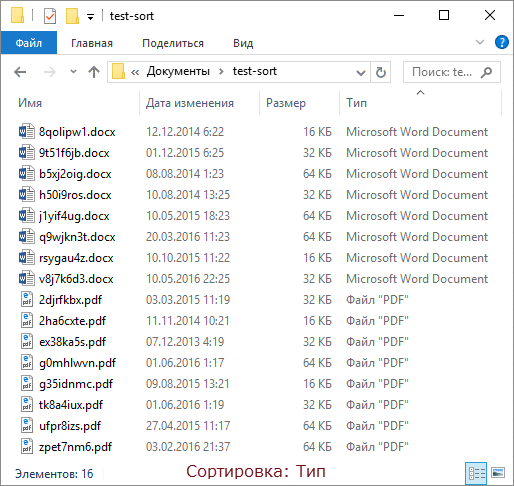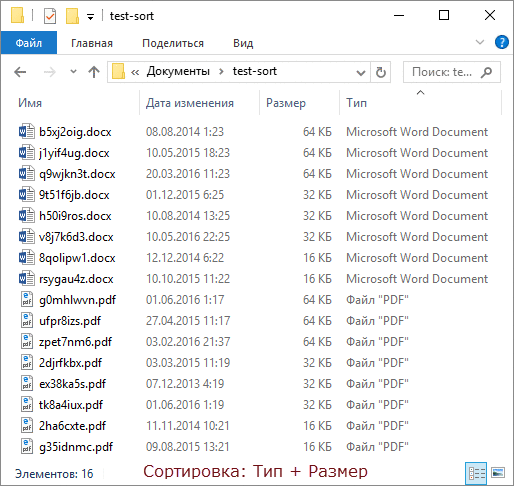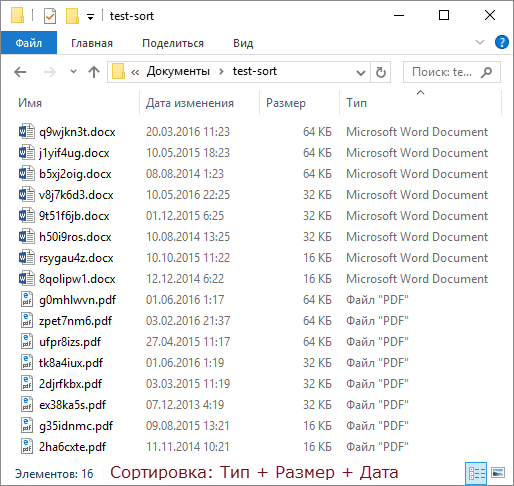
Open the Documents folder in Explorer and sort the content by modified date. What's on top - folders or files? The correct answer depends on how you opened the folder :)
Regular readers have already guessed that today they will not do without - interesting, but so plainly and did not take root. It would seem that in Windows 10 libraries have faded into the background, but a lot is tied to them.
Today in the program
About the role of libraries in Windows 10
Indeed, in the explorer folders Documents, Pictures and Music took over the Computer and the Quick Launch, and the Libraries disappeared from the navigation area. But they rely on file history (as we found out in the previous post) and legacy image backup from Windows 7 (with the old rake).
And most importantly, the libraries are present in standard dialogs, and the window opens exactly in library, including in store apps.
It is proposed to add a folder from the Documents library to the Images library as a source of photos
At the same time, Microsoft did not manage to implant the libraries into the shell, and today I will sort out another confusion.
Sort mismatch
Depending on whether you open a folder from the library or bypassing it, not only the appearance may vary, but also the sorting by date. Run a simple experiment (the result below is correct with default Explorer settings):
- Open the document folder from the Navigation Pane or Win + R → Documents and sort it by date modified. Recent files will appear at the top of the list.
- Open the same folder from the library: Win + R → shell: documentsLibrary and do the same sorting. It's at the top of the list of folders, and you have to scroll down to get to the files.
It is easy to determine by the address bar whether the folder is open from the library or directly (I analyzed this in a quiz 5 years ago).
 Difference in sorting by modified date between folders and libraries with default Explorer settings
Difference in sorting by modified date between folders and libraries with default Explorer settings
It makes sense to bring the settings to a single form so as not to get confused. This is useful even if you are not using libraries on purpose, as you will stumble upon them in dialog boxes for desktop and store applications.
The only question is which way of displaying the results is prettier to you!
I'm sure experienced users often use the first option - with files at the top. Sorting by date, we still often look for a file in a known folder, and there is no point in spinning the mouse wheel again. But the option with folders on top has the right to life, so I'll come back to it when I deal with the libraries.
Sorting in libraries
You can puzzle for a long time if you do not know about one feature of the libraries. When you open a folder from the library, along with grouping and sorting, it becomes possible streamlining files, which I talked about in the classic penalty shootout "Explorer vs. TC ".
Interestingly, in Windows 7, ordering was moved to a special library panel at the top of the explorer window. But Windows 8 has updated it a lot and the ordering is only left in the context menu.
Libraries: sort by date - "files always on top"
Right-click on an empty space in the folder. And here is the reason that folders in libraries are always at the top - they are ordered by them!
 Background context menu of a folder opened from a library
Background context menu of a folder opened from a library
Switch ordering to Name and sort the folder by modified date. Now the recent files are on top, which is what you had to prove!
Sort in folders
Now it will be more interesting! Let's say you downloaded the seventh season of your favorite TV series to the Movies folder, all episodes of which were placed in a subfolder. At the root of Movies, you have many separate files - movies, torrent files, etc. The usual sorting by date does not help here, because the folders settle down below - under the files.
 Normal sorting a folder by date in a folder
Normal sorting a folder by date in a folder
Sorting by name will bring folders up, but the new folder will get lost in their list, and you still have to look for it with your eyes.
Folders: sort by date - "folders always at the top"
The secret solution has been in Explorer since Windows Vista.
- Click a column Date of changeso that the new is on top.
- Shift-click a column A type (will also work Name).
The folders will be displayed sorted by date at the top, and the fresh folder will be at the very top!
 The sort indicator in the explorer always points to the main column, and the additional criteria are not indicated in any way
The sort indicator in the explorer always points to the main column, and the additional criteria are not indicated in any way
Explorer remembers the combined sorting state, but you can reset it by first holding Ctrl, click on the same column, and then sort by modified date as usual.
Folders: sort by several criteria
Sorting by date is the most common question, but the Shift trick works with any column, and you can apply multiple sorting criteria at the same time!
To demonstrate this, I generated a dozen files of two types with different sizes and creation dates, and for clarity, I made a GIF with four sorting states.
In order of frames:
- Initially, folders are sorted by name.
- We sort by type in the usual way.
- We sort with Shift by size, and files of each type are arranged in descending order of size.
- We sort with Shift by date modified, and files of the same size are lined up from newest to oldest!
Working! :)
Bonus: sorting in Total Commander
After reading the article to this point, some of you, I think, have already checked whether the Shift trick works in your favorite file manager. Total Commander can do that too! Moreover, his implementation is more visual.
 Total Commander has arrows and a sorting number in the columns, and the main column is highlighted
Total Commander has arrows and a sorting number in the columns, and the main column is highlighted
I think this should work in other two-pane managers too - write in the comments!
Rake
There are a couple of things to consider.
- In Explorer, the Shift trick has a limitation - it doesn't work when the viewport is active, but it quickly switches with Alt + P.
- Instead of this trick, when dealing with sorting by date, there are tips on the web to use a column date instead Date of change... This is fraught with created a year ago and the document downloaded today will not be at the top of the list.
History of the issue
Usually, I use this subtitle to talk about the evolution of this or that feature, but today I will entertain you with a story about the difficult path of this article to light.
Question about libraries a reader asked me in the mail Evgeny K... Having rummaged through the blog, I found out that I did not publish a specific solution, and it did not attract a new separate article. I sent a reply by mail and made a note to write about it on social networks. But the thought that I had already written on this topic stuck in my head.
I went through OneNote and found a mention of Shift sorting! It appeared in the outline for the article published four (!) Years ago, 14 ways to use a mouse in conjunction with a keyboard to speed up work. Obviously, I then decided that the trick deserves a separate material to continue the topic (and even made a note of ToDo :)
OneNote Archive 2012 Sketches
Now I have delivered the fifteenth method to you :) Better late than never!
Discussion
We've discussed file managers and File Explorer in particular so many times that it's hard to come up with a new topic for discussion. In comments:
- write if you knew about this sorting trick and how useful it [will be] to you in everyday tasks
- share the techniques that you use when you need to get to the files or folders you need as quickly as possible, incl. in windows Open / Save as
Access provides several ways to sort the data retrieved through a query. You can quickly sort in the query window with the command Sorting from the menu Entries, and also buttons Ascendingand Descending toolbars. To do this, include in the query the table fields by which the records will be sorted, and determine the sorting method - ascending or descending. The data can be sorted alphabetically, ascending or descending. Ascending alphanumeric sort sorts data in this order: first, items that start with punctuation or special characters, then items that start with numbers, and then items that begin with letters.
Sorting data in a table by the contents of only one column does not always lead to the desired results, so sometimes you need to sort by the contents of several fields.
Note:To speed up sorting, you should place the fields next to them, the data of which you want to sort.
Through the query window, new records can be inserted into the original table, as if filling the table. The added or modified data is placed in the table from which the query is created. As a result of entering new data into the table, the order of the data in the query may be out of order. To restore the order, you need to repeat the request call and data sorting.
You can also sort the data in the query designer window. To do this, press the button Open in the tab Inquiries database windows. In the window for selecting tables, mark the name of the table in which the data should be sorted, and then click Add to and Close. Mark all field names in the list by double-clicking on the list header and move it to the QBE area. For the required field set in line Sorting sorting method . Save the request.
Application of special criteria
So far, we've looked at queries that select table fields. When creating a query, you can set additional criteria, as a result of which it will select only the necessary information in each field. To form such a query, you must enter a value in the QBE area in the cell located at the intersection of the line Selection conditions and columns with the desired name.
The criteria set in the QBE area must be enclosed in quotation marks. If Access identifies the entered characters as a selection criterion, it automatically quotes them, and if not, it reports a syntax error. Access cannot recognize a combination of characters and wildcards as a criterion.
Note:The wildcard characters * and? they are used in the same way as in all Microsoft Office 97 applications. The asterisk character stands for any number of letters or numbers, and the question mark stands for only one character.
All lines in the QBE area below the line Selection conditions, serve to set selection criteria. Thus, for one field, you can define two, three or more data selection criteria. By default, all elements of the criterion are combined by the operator OR... This means that the query will select those records that meet at least one criterion.
To combine multiple selection conditions by an operator AND, you should bring them on one line. For example, if you need to select records from a table Salary, in which salaries from 310 to 1500 are indicated, then in the column Salary the following criterion should be introduced: Bet ween 310 and 1500 ... Another form of writing this criterion is the expression > 310 And <1500 .
As a result, only those records will be selected that satisfy both conditions, i.e. salaries, the values \u200b\u200bof which are in the range from 310 to 1500.
If you need to select several ranges of values, then the criterion for each range should be specified on a separate line.
The following criterion allows excluding a data group from the composition of the records analyzed by the query (for example, salary 400): Not 400 ... Another form of writing this criterion: <>400 ... In this case, you do not need to use quotation marks.
Operators Andand Orapplied both separately and together. It should be remembered that the conditions associated with the operator And, are met before the conditions combined by the operator Or.
When fetching data, it can be important to get them in a certain ordered form. Sorting can be performed by any field with any data type. This can be ascending or descending sort for numeric fields. For character (text) fields, this can be an alphabetical sort, although in essence it is also an ascending or descending sort. It can also be performed in any direction - from A to Z, and vice versa from Z to A.
The essence of the sorting process is to bring the sequence to a certain order. You can learn more about sorting in the article "Sorting algorithms" For example, sorting an arbitrary numerical sequence in ascending order:
2, 4, 1, 5, 9
should result in an ordered sequence:
1, 2, 4, 5, 6
Similarly, when sorting ascending string values:
Ivanov Ivan, Petrov Peter, Ivanov Andrey
the result should be:
Ivanov Andrey, Ivanov Ivan, Petrov Petr
Here the line "Ivanov Andrey" went to the beginning, since the comparison of strings is performed character by character. Both lines begin with the same characters "Ivanov". Since the character "A" in the word "Andrey" comes earlier in the alphabet than the character "I" in the word "Ivan", this line will be placed earlier.
Sorting in SQL Query
To perform sorting, the ORDER BY command must be added to the query string. After this command, the field by which the sorting is performed is indicated.
For examples, we use the goods table:
| num (Item Number) | title (name) | price (price) |
| 1 | Mandarin | 50 |
| 2 | Watermelon | 120 |
| 3 | A pineapple | 80 |
| 4 | Banana | 40 |
The data is already sorted by the "num" column. Now, let's build a query that will display a table with products sorted alphabetically:
SELECT * FROM goods ORDER BY title
SELECT * FROM goods - indicates to select all fields from the goods table;
ORDER BY - sorting command;
title - the column to sort by.
The result of executing such a query is as follows:
| num | title | price |
| 3 | A pineapple | 80 |
| 2 | Watermelon | 120 |
| 4 | Banana | 40 |
| 1 | Mandarin | 50 |
You can also sort for any of the table fields.
Sorting direction
By default, ORDER BY sorts in ascending order. To manually control the sort direction, the keyword ASC (ascending) or DESC (descending) is specified after the column name. Thus, in order to display our table in descending order of prices, we need to set the query like this:
SELECT * FROM goods ORDER BY price DESC
Sorting in ascending order of price will be:
SELECT * FROM goods ORDER BY price ASC
Sorting by multiple fields
SQL allows sorting by several fields at once. To do this, after the ORDER BY command, the required fields are separated by commas. The order in the query result will be adjusted in the same order in which the sort fields are specified.
| column1 | column2 | column3 |
| 3 | 1 | c |
| 1 | 3 | c |
| 2 | 2 | b |
| 2 | 1 | b |
| 1 | 2 | a |
| 1 | 3 | a |
| 3 | 4 | a |
Let's sort the table according to the following rules:
SELECT * FROM mytable ORDER BY column1 ASC, column2 DESC, column3 ASC
Those. the first column is ascending, the second is descending, the third is again ascending. The query will order the rows by the first column, then, without breaking the first rule, by the second column. Then, in the same way, without violating the existing rules, according to the third. The result will be the following dataset:
| column1 | column2 | column3 |
| 1 | 3 | a |
| 1 | 3 | c |
| 1 | 2 | a |
| 2 | 2 | b |
| 2 | 1 | b |
| 3 | 1 | a |
| 3 | 1 | c |
ORDER BY command order in a query
Sorting of rows is most often carried out together with a condition for data selection. The ORDER BY command is placed after the WHERE selection condition. For example, we select products with a price less than 100 rubles, sorting by name in alphabetical order:
SELECT * FROM goods WHERE price 100 ORDER BY price ASC