Скачать robots txt для яндекса. Как редактировать файл robots txt. User-agent с пустым значением
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Robots.txt - это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это - указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие - нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.
Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.

Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение.txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые - только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.
Такой вариант, наоборот, означает полный запрет индексации для всех.
Запрет на просмотр всего содержимого определенной папки-каталога
Для блокировки одного файла нужно указать его абсолютный путь
Директивы Sitemap, Host
Для Яндекса в принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.
Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.
Директива Crawl-delay
С помощью можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.
Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
Всем привет! Сегодня я бы хотел Вам рассказать про файл robots.txt . Да, про него очень много чего написано в интернете, но, если честно, я сам очень долгое время не мог понять, как же создать правильный robots.txt. В итоге я сделал один и он стоит на всех моих блогах. Проблем с я не замечаю, robots.txt работает просто великолепно.
Robots.txt для WordPress
А зачем, собственно говоря, нужен robots.txt? Ответ все тот же – . То есть составление robots.txt – это одно из частей поисковой оптимизации сайта (кстати, очень скоро будет урок, который будет посвящен всей внутренней оптимизации сайта на WordPress. Поэтому не забудьте подписаться на RSS , чтобы не пропустить интересные материалы.).
Одна из функций данного файла – запрет индексации ненужных страниц сайта. Также в нем задается адрес и прописывается главное зеркало сайта (сайт с www или без www).
Примечание: для поисковых систем один и тот же сайт с www и без www совсем абсолютно разные сайты. Но, поняв, что содержимое этих сайтов одинаковое, поисковики “склеивают” их. Поэтому важно прописать главное зеркало сайта в robots.txt. Чтобы узнать, какое главное (с www или без www), просто наберите адрес своего сайта в браузере, к примеру, с www, если Вас автоматически перебросит на тот же сайт без www, значит главное зеркало Вашего сайта без www. Надеюсь правильно объяснил.
Так вот, этот заветный, по-моему, правильный robots.txt для WordPress Вы можете увидеть ниже.
Правильный Robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /*?*
Disallow: /tag
Host: сайт
.gz
Sitemap: https://сайт/sitemap.xml
Все что дано выше, Вам нужно скопировать в текстовой документ с расширением.txt, то есть, чтобы название файла было robots.txt. Данный текстовой документ Вы можете создать, к примеру, с помощью программы . Только, не забудьте, пожалуйста, изменить в последних трех строчках адрес на адрес своего сайта. Файл robots.txt должен располагаться в корне блога, то есть в той же папке, где находятся папки wp-content, wp-admin и др. .
Те, кому же лень создавать данный текстовой файл, можете просто скачать robots.txt и также там подкорректировать 3 строчки.
Хочу отметить, что в техническими частями, о которых речь пойдет ниже, себя сильно загружать не нужно. Привожу их для “знаний”, так сказать общего кругозора, чтобы знали, что и зачем нужно.
Итак, строка:
User-agent
задает правила для какого-то поисковика: к примеру “*” (звездочкой) отмечено, что правила для всех поисковиков, а то, что ниже
User-agent: Yandex
означает, что данные правила только для Яндекса.
Disallow
Здесь же Вы “засовываете” разделы, которые НЕ нужно индексировать поисковикам. К примеру, на странице https://сайт/tag/seo у меня идет дубль статей (повторение) с обычными статьями, а дублирование страниц отрицательно сказывается на поисковом продвижении, поэтому, крайне желательно, данные секторы нужно закрыть от индексации, что мы и делаем с помощью этого правила:
Disallow: /tag
Так вот, в том robots.txt, который дан выше, от индексации закрыты почти все ненужные разделы сайта на WordPress, то есть просто оставьте все как есть.
Host
Здесь мы задаем главное зеркало сайта, о котором я рассказывал чуть выше.
Sitemap
В последних двух строчках мы задаем адрес до двух карт сайта, созданные с помощью .
Возможные проблемы
А вот из-за этой строчки в robots.txt, у меня перестали индексироваться посты сайта:
Disallow: /*?*
Как видите, эта самая строка в robots.txt запрещает индексирование статей, что естественно нам нисколько не нужно. Чтобы исправить это, просто нужно удалить эти 2 строчки (в правилах для всех поисковиков и для Яндекса) и окончательный правильный robots.txt для WordPress сайта без ЧПУ будет выглядеть следующим образом:
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Host: сайт
Sitemap: https://сайт/sitemap.xml
Чтобы проверить, правильно ли мы составили файл robots.txt я рекомендую Вам воспользоваться сервисом Яндекс Вебмастер (как регистрироваться в данном сервисе я рассказывал ).
Заходим в раздел Настройки индексирования –> Анализ robots.txt:
Уже там нажимаете на кнопку “Загрузить robots.txt с сайта”, а затем нажимаете на кнопку “Проверить”:
Если Вы увидите примерно следующее сообщение, значит у Вас правильный robots.txt для Яндекса:

В SEO мелочей не бывает. Иногда на продвижение сайта может оказать влияние всего лишь один небольшой файл — Robots.txt. Если вы хотите, чтобы ваш сайт зашел в индекс, чтобы поисковые роботы обошли нужные вам страницы, нужно прописать для них рекомендации.
«Разве это возможно?» , — спросите вы. Возможно. Для этого на вашем сайте должен быть файл robots.txt. Как правильно составить файл роботс , настроить и добавить на сайт – разбираемся в этой статье.
Что такое robots.txt и для чего нужен
Robots.txt – это обычный текстовый файл , который содержит в себе рекомендации для поисковых роботов: какие страницы нужно сканировать, а какие нет.
Важно: файл должен быть в кодировке UTF-8, иначе поисковые роботы могут его не воспринять.
Зайдет ли в индекс сайт, на котором не будет этого файла? Зайдет, но роботы могут «выхватить» те страницы, наличие которых в результатах поиска нежелательно: например, страницы входа, админпанель, личные страницы пользователей, сайты-зеркала и т.п. Все это считается «поисковым мусором»:
Если в результаты поиска попадёт личная информация, можете пострадать и вы, и сайт. Ещё один момент – без этого файла индексация сайта будет проходить дольше.
В файле Robots.txt можно задать три типа команд для поисковых пауков:
- сканирование запрещено;
- сканирование разрешено;
- сканирование разрешено частично.
Все это прописывается с помощью директив.
Как создать правильный файл Robots.txt для сайта
Файл Robots.txt можно создать просто в программе «Блокнот», которая по умолчанию есть на любом компьютере. Прописывание файла займет даже у новичка максимум полчаса времени (если знать команды).
Также можно использовать другие программы – Notepad, например. Есть и онлайн сервисы, которые могут сгенерировать файл автоматически. Например, такие как CY-PR.com или Mediasova .
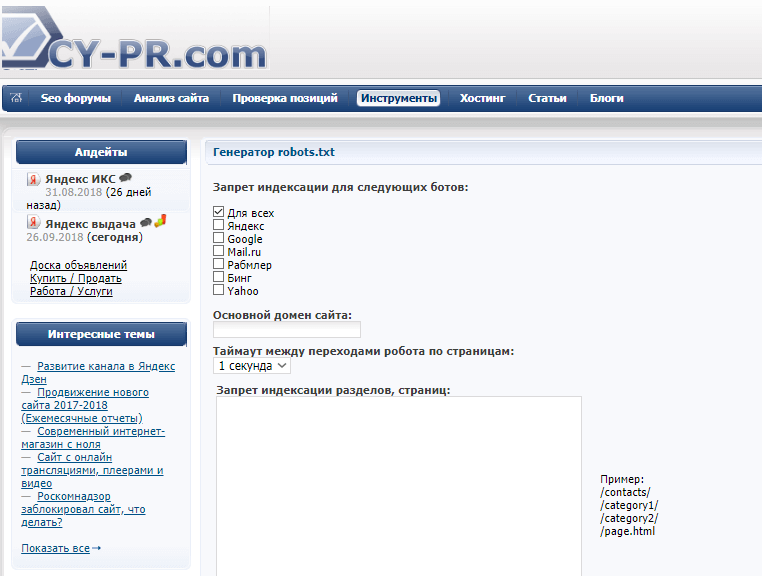
Вам просто нужно указать адрес своего сайта, для каких поисковых систем нужно задать правила, главное зеркало (с www или без). Дальше сервис всё сделает сам.
Лично я предпочитаю старый «дедовский» способ – прописать файл вручную в блокноте. Есть ещё и «ленивый способ» — озадачить этим своего разработчика 🙂 Но даже в таком случае вы должны проверить, правильно ли там всё прописано. Поэтому давайте разберемся, как составить этот самый файл, и где он должен находиться.
Готовый файл Robots.txt должен находиться в корневой папке сайта. Просто файл, без папки:

Хотите проверить, есть ли он на вашем сайте? Вбейте в адресную строку адрес: site.ru/robots.txt . Вам откроется вот такая страничка (если файл есть):

Файл состоит из нескольких блоков, отделённых отступом. В каждом блоке – рекомендации для поисковых роботов разных поисковых систем (плюс блок с общими правилами для всех), и отдельный блок со ссылками на карту сайта – Sitemap.
Внутри блока с правилами для одного поискового робота отступы делать не нужно.
Каждый блок начинается директивой User-agent.
После каждой директивы ставится знак «:» (двоеточие), пробел, после которого указывается значение (например, какую страницу закрыть от индексации).
Нужно указывать относительные адреса страниц, а не абсолютные. Относительные – это без «www.site.ru». Например, вам нужно запретить к индексации страницу www.site.ru/shop . Значит после двоеточия ставим пробел, слэш и «shop»:
Disallow: /shop.
Звездочка (*) обозначает любой набор символов.
Знак доллара ($) – конец строки.
Вы можете решить – зачем писать файл с нуля, если его можно открыть на любом сайте и просто скопировать себе?
Для каждого сайта нужно прописывать уникальные правила. Нужно учесть особенности CMS . Например, та же админпанель находится по адресу /wp-admin на движке WordPress, на другом адрес будет отличаться. То же самое с адресами отдельных страниц, с картой сайта и прочим.
Настройка файла Robots.txt: индексация, главное зеркало, диррективы
Как вы уже видели на скриншоте, первой идет директива User-agent. Она указывает, для какого поискового робота будут идти правила ниже.
User-agent: * — правила для всех поисковых роботов, то есть любой поисковой системы (Google, Yandex, Bing, Рамблер и т.п.).
User-agent: Googlebot – указывает на правила для поискового паука Google.
User-agent: Yandex – правила для поискового робота Яндекс.
Для какого поискового робота прописывать правила первым, нет никакой разницы. Но обычно сначала пишут рекомендации для всех роботов.
Disallow: Запрет на индексацию
Чтобы запретить индексацию сайта в целом или отдельных страниц, используется директива Disallow.
Например, вы можете полностью закрыть сайт от индексации (если ресурс находится на доработке, и вы не хотите, чтобы он попал в выдачу в таком состоянии). Для этого нужно прописать следующее:
User-agent: *
Disallow: /
Таким образом всем поисковым роботам запрещено индексировать контент на сайте.
А вот так можно открыть сайт для индексации:
User-agent: *
Disallow:
Потому проверьте, стоит ли слеш после директивы Disallow, если хотите закрыть сайт. Если хотите потом его открыть – не забудьте снять правило (а такое часто случается).
Чтобы закрыть от индексации отдельные страницы, нужно указать их адрес. Я уже писала, как это делается:
User-agent: *
Disallow: /wp-admin
Таким образом на сайте закрыли от сторонних взглядов админпанель.
Что нужно закрывать от индексации в обязательном порядке:
- административную панель;
- личные страницы пользователей;
- корзины;
- результаты поиска по сайту;
- страницы входа, регистрации, авторизации.
Можно закрыть от индексации и отдельные типы файлов. Допустим, у вас на сайте есть некоторые.pdf-файлы, индексация которых нежелательна. А поисковые роботы очень легко сканируют залитые на сайт файлы. Закрыть их от индексации можно следующим образом:
User-agent: *
Disallow: /*. pdf$
Как отрыть сайт для индексации
Даже при полностью закрытом от индексации сайте можно открыть роботам путь к определённым файлам или страницам. Допустим, вы переделываете сайт, но каталог с услугами остается нетронутым. Вы можете направить поисковых роботов туда, чтобы они продолжали индексировать раздел. Для этого используется директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Главное зеркало сайта
До 20 марта 2018 года в файле robots.txt для поискового робота Яндекс нужно было указывать главное зеркало сайта через директиву Host. Сейчас этого делать не нужно – достаточно настроить постраничный 301-редирект .
Что такое главное зеркало? Это какой адрес вашего сайта является главным – с www или без. Если не настроить редирект, то оба сайта будут проиндексированы, то есть, будут дубли всех страниц.
Карта сайта: robots.txt sitemap
После того, как прописаны все директивы для роботов, необходимо указать путь к Sitemap. Карта сайта показывает роботам, что все URL, которые нужно проиндексировать, находятся по определённому адресу. Например:
Sitemap: site.ru/sitemap.xml
Когда робот будет обходить сайт, он будет видеть, какие изменения вносились в этот файл. В итоге новые страницы будут индексироваться быстрее.
Директива Clean-param
В 2009 году Яндекс ввел новую директиву – Clean-param. С ее помощью можно описать динамические параметры, которые не влияют на содержание страниц. Чаще всего данная директива используется на форумах. Тут возникает много мусора, например id сессии, параметры сортировки. Если прописать данную директиву, поисковый робот Яндекса не будет многократно загружать информацию, которая дублируется.
Прописать эту директиву можно в любом месте файла robots.txt.
Параметры, которые роботу не нужно учитывать, перечисляются в первой части значения через знак &:
Clean-param: sid&sort /forum/viewforum.php
Эта директива позволяет избежать дублей страниц с динамическими адресами (которые содержат знак вопроса).
Директива Crawl-delay
Эта директива придёт на помощь тем, у кого слабый сервер.
Приход поискового робота – это дополнительная нагрузка на сервер. Если у вас высокая посещаемость сайта, то ресурс может попросту не выдержать и «лечь». В итоге робот получит сообщение об ошибке 5хх. Если такая ситуация будет повторяться постоянно, сайт может быть признан поисковой системой нерабочим.
Представьте, что вы работаете, и параллельно вам приходится постоянно отвечать на звонки. Ваша продуктивность в таком случае падает.
Так же и с сервером.
Вернемся к директиве. Crawl-delay позволяет задать задержку сканирования страниц сайта с целью снизить нагрузку на сервер. Другими словами, вы задаете период, через который будут загружаться страницы сайта. Указывается данный параметр в секундах, целым числом:
Приветствую вас, уважаемые читатели SEO блога Pingo. В данной статье я хочу изложить своё представление о том, как правильно составить robots.txt для сайта. В своё время меня очень раздражало, что информация в интернете по этому вопросу довольно отрывочна. Из-за этого приходилось ползать по большому количеству ресурсов, постоянно фильтруя повторяющуюся информацию и вычленяя новую.
Таким образом, здесь я постараюсь ответить на большинство вопросов, начиная с определения и заканчивая примерами реальных задач, решаемых данным инструментом. Если что-то забуду - отпишитесь в комментариях об этом - исследую вопрос и дополню материал.
Robots.txt - что это, зачем нужен и где обитает?
Итак, сперва ликбез для тех, кому данная тема незнакома совершенно.
Robots.txt - текстовый файл, содержащий инструкции по индексации сайта для роботов поисковых систем. В этом файле вебмастер может определить параметры индексации своего сайта как для всех роботов сразу, так и для каждой поисковой системы по отдельности (например, для гугла).
Где находится robots.txt? Он размещается в корневой папке FTP сайта, и, по сути, является обычным документом в формате txt, редактирование которого можно осуществлять через любой текстовый редактор (лично я предпочитаю Notepad++). Содержимое файла роботс можно увидеть, введя в адресной строке браузера http://www.ваш-сайт.ru/robots.txt. Если, конечно, он существует.
Как создать robots.txt для сайта? Достаточно сделать обычный текстовый файл с таким именем и загрузить его на сайт. О том, как его правильно настроить и составить, будет сказано ниже.
Структура и правильная настройка файла robots.txt
Как должен выглядеть правильный файл robots txt для сайта? Структуру можно описать следующим образом:
1. Директива User-agent
Что писать в данном разделе? Эта директива определяет то, для какого именно робота предназначены нижеизложенные инструкции. Например, если они предназначены для всех роботов, то достаточно следующей конструкции:
В синтаксисе файла robots.txt знак «*» равноценен словосочетанию «что угодно». Если же требуется задать инструкции для конкретной поисковой системы или робота, то на месте звездочки из предыдущего примера пишется его название, например:
User-agent: YandexBot
У каждого поисковика существует целый набор роботов, выполняющих те или иные функции. Роботы поисковой системы Яндекс описаны . В общем же плане имеется следующее:
- Yandex - указание на роботов Яндекс.
- GoogleBot - основной индексирующий робот .
- MSNBot - основной индексирующий робот Bing.
- Aport - роботы Aport.
- Mail.Ru - роботы ПС Mail.
Если имеется директива для конкретной поисковой системы или робота, то общие игнорируются.
2. Директива Allow
Разрешает отдельные страницы раздела, если, скажем, ранее он целиком закрыт от индексации. Например:
User-agent: *
Disallow: /
Allow: /открытая-страница.html
В данном примере мы запрещаем к индексации весь сайт, кроме страницы poni.html
Служит эта директива в какой-то степени для указания на исключения из правил, заданных директивой Disallow. В случае, если таких ситуаций нет, то директива может не использоваться совсем. Она не позволяет открыть сайт для индексации, как многие думают, так как если нет запрета вида Disallow: /, то он открыт по умолчанию.
2. Директива Disallow
Является антиподом директивы Allow и закрывает от индексации отдельные страницы, разделы или сайт целиком. Являет аналогом тега noindex. Например:
User-agent: *
Disallow: /закрытая-страница.html
3. Директива Host
Используется только для Яндекса и указывает на основное зеркало сайта. Выглядит это так.
Основное зеркало без www:
Основное зеркало с www:
Host: www.site.ru
Сайт на https:
Host: https://site.ru
Нельзя записывать директиву host в файл дважды. Если же вследствие какой-то ошибки это произошло, то обрабатывается та директива, которая идет первой, а вторая - игнорируется.
4. Директива Sitemap
Используется для указания пути к XML-карте сайта sitemap.xml (если она есть). Синтаксис следующий:
Sitemap: http://www.site.ru/sitemap.xml
5. Директива Clean-param
Используется для закрытия от индексации страниц с параметрами, которые могут являться дублями. Очень полезная на мой взгляд директива, которая отсекает параметрический хвост урлов, оставляя только костяк, который и является родоначальным адресом страницы.
Особенно часто встречается такая проблема при работе с каталогами и интернет-магазинами.
Скажем, у нас имеется страница:
http://www.site.ru/index.php
И эта страница в процессе работы может обрастать клонами вида.
http://www.site.ru/index.php?option=com_user_view=remind
http://www.site.ru/index.php?option=com_user_view=reset
http://www.site.ru/index.php?option=com_user_view=login
Для того, чтобы избавиться от всевозможных вариантов этого спама, достаточно указать следующую конструкцию:
Clean-param: option /index.php
Синтаксис из примера, думаю, понятен:
Clean-param: # указываем директиву
option # указываем спамный параметр
/index.php # указываем костяк урла со спамным параметром
Если параметров несколько, то просто перечисляем их через амперсант(&):
http://www.site.ru/index.php?option=com_user_view=remind&size=big # урл с двумя параметрами
Clean-param: option&big /index.php # указаны два параметра через амперсант
Пример взят простой, поясняющий саму суть. Особенно спасибо этому параметру хочется сказать при работе с CMS Bitrix.
Директива Crawl-Delay
Позволяет задать таймаут на загрузку страниц сайта роботом Яндекс. Используется при большой загруженности сервера, при которой он просто не успевает быстро отдавать содержимое. На мой взгляд, это анахронизм, который уже не учитывается и который можно не использовать.
Crawl-delay: 3.5 #таймаут в 3,5 секунды
Синтаксис
- # - используется для написания комментариев:
- * - означает любую последовательность символов, значение:
- $ - обрезание правила, антипод знака звездочки:
User-agent: * # директива относится ко всем роботам
Disallow: /page* # запрет всех страниц, начинающихся на page
Disallow: /*page # запрет всех страниц, заканчивающихся на page
Disallow: /cgi-bin/*.aspx # запрет всех aspx страниц в папке cgi-bin
Disallow: /page$ # будет закрыта только страница /page, а не /page.html или pageline.html
Пример файла robots.txt
С целью закрепления понимания вышеописанной структуры и правил, приведем стандартный robots txt для CMS Data Life Engine.
User-agent: * # директивы предназначены для всех поисковых систем
Disallow: /engine/go.php # запрещаем отдельные разделы и страницы
Disallow: /engine/download.php #
Disallow: /user/ #
Disallow: /newposts/ #
Disallow: /*subaction=userinfo # закрываем страницы с отдельными параметрами
Disallow: /*subaction=newposts #
Disallow: /*do=lastcomments #
Disallow: /*do=feedback #
Disallow: /*do=register #
Disallow: /*do=lostpassword #
Host: www.сайт # указываем главное зеркало сайта
Sitemap: https://сайт/sitemap.xml # указываем путь до карты сайта
User-agent: Aport # указываем направленность правил на ПС Aport
Disallow: / # предположим, не хотим мы с ними дружить
Проверка robots.txt
Как проверить robots txt на корректность составления? Стандартный вариант - валидатор Яндекса - http://webmaster.yandex.ru/robots.xml . Вводим путь до вашего файла роботс или сразу вставляем его содержимое в текстовое поле. Вводим список урлов, которые мы хотим проверить - закрыты или открыты они согласно заданным директивам - нажимаем «Проверить» и вуаля! Профит.
Выводится статус страницы - открыта ли она для индексации или закрыта. Если закрыта, то указывается, каким именно правилом. Чтобы разрешить индексацию такой страницы, нужно доработать правило, на которое указывает валидатор. Если в файле имеются синтаксические ошибки, то валидатор также об этом сообщит.
Генератор robots.txt - создание в режиме онлайн
Если изучать синтаксис желания или времени нет, но необходимость закрыть спамные страницы сайта присутствует, то можно воспользоваться любым бесплатным онлайн генератором , который позволит создать robots txt для сайта всего парой кликов. Затем вам останется лишь скачать файл и загрузить его к себе на сайт. При работе с ним вам лишь необходимо проставить галочки у очевидных настроек, а также указать страницы, которые вы хотите закрыть от индексации. Остальное генератор сделает за вас.

Готовые файлы для популярных CMS
Файл robots.txt для сайта на 1C Битрикс
User-Agent: *
Disallow: /bitrix/
Disallow: /personal/
Disallow: /upload/
Disallow: /*login*
Disallow: /*auth*
Disallow: /*search
Disallow: /*?sort=
Disallow: /*gclid=
Disallow: /*register=
Disallow: /*?per_count=
Disallow: /*forgot_password=
Disallow: /*change_password=
Disallow: /*logout=
Disallow: /*back_url_admin=
Disallow: /*print=
Disallow: /*backurl=
Disallow: /*BACKURL=
Disallow: /*back_url=
Disallow: /*BACK_URL=
Disallow: /*ADD2BASKET
Disallow: /*ADD_TO_COMPARE_LIST
Disallow: /*DELETE_FROM_COMPARE_LIST
Disallow: /*action=BUY
Disallow: /*set_filter=y
Disallow: /*?mode=matrix
Disallow: /*?mode=listitems
Disallow: /*openstat
Disallow: /*from=adwords
Disallow: /*utm_source
Host: www.site.ru
Robots.txt для DataLife Engine (DLE)
User-agent: *
Disallow: /engine/go.php
Disallow: /engine/download.php
Disallow: /engine/classes/highslide/
Disallow: /user/
Disallow: /tags/
Disallow: /newposts/
Disallow: /statistics.html
Disallow: /*subaction=userinfo
Disallow: /*subaction=newposts
Disallow: /*do=lastcomments
Disallow: /*do=feedback
Disallow: /*do=register
Disallow: /*do=lostpassword
Disallow: /*do=addnews
Disallow: /*do=stats
Disallow: /*do=pm
Disallow: /*do=search
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Joomla
User-agent: *
Disallow: /administrator/
Disallow: /cache/
Disallow: /includes/
Disallow: /installation/
Disallow: /language/
Disallow: /libraries/
Disallow: /media/
Disallow: /modules/
Disallow: /plugins/
Disallow: /templates/
Disallow: /tmp/
Disallow: /xmlrpc/
Disallow: *print
Disallow: /*utm_source
Disallow: /*mailto*
Disallow: /*start*
Disallow: /*feed*
Disallow: /*search*
Disallow: /*users*
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Wordpress
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: */trackback
Disallow: */feed
Disallow: /wp-login.php
Disallow: /wp-register.php
Host: www.site.ru
Sitemap: http://www.site.ru/sitemap.xml
Robots.txt для Ucoz
User-agent: *
Disallow: /a/
Disallow: /stat/
Disallow: /index/1
Disallow: /index/2
Disallow: /index/3
Disallow: /index/5
Disallow: /index/7
Disallow: /index/8
Disallow: /index/9
Disallow: /panel/
Disallow: /admin/
Disallow: /secure/
Disallow: /informer/
Disallow: /mchat
Disallow: /search
Disallow: /shop/order/
Disallow: /?ssid=
Disallow: /google
Disallow: /
Файл robots.txt — текстовый файл в формате.txt, ограничивающий поисковым роботам доступ к содержимому на http-сервере. Как определение, Robots.txt — это стандарт исключений для роботов , который был принят консорциумом W3C 30 января 1994 года, и который добровольно использует большинство поисковых систем. Файл robots.txt состоит из набора инструкций для поисковых роботов, которые запрещают индексацию определенных файлов, страниц или каталогов на сайте. Рассмотрим описание robots.txt для случая, когда сайт не ограничивает доступ роботам к сайту.
Простой пример robots.txt:
User-agent: * Allow: /
Здесь роботс полностью разрешает индексацию всего сайта.
Файл robots.txt необходимо загрузить в корневой каталог вашего сайта , чтобы он был доступен по адресу:
Ваш_сайт.ru/robots.txt
Для размещения файла robots.txt в корне сайта обычно необходим доступ через FTP . Однако, некоторые системы управления (CMS) дают возможность создать robots.txt непосредственно из панели управления сайтом или через встроенный FTP-менеджер.
Если файл доступен, то вы увидите содержимое robots.txt в браузере.
Для чего нужен robots.txt
Roots.txt для сайта является важным аспектом . Зачем нужен robots.txt ? Например, в SEO robots.txt нужен для того, чтобы исключать из индексации страницы, не содержащие полезного контента и многое другое . Как, что, зачем и почему исключается уже было описано в статье про , здесь не будем на этом останавливаться. Нужен ли файл robots.txt всем сайтам? И да и нет. Если использование robots.txt подразумевает исключение страниц из поиска, то для небольших сайтов с простой структурой и статичными страницами подобные исключения могут быть лишними. Однако, и для небольшого сайта могут быть полезны некоторые директивы robots.txt , например директива Host или Sitemap, но об этом ниже.
Как создать robots.txt
Поскольку robots.txt — это текстовый файл, и чтобы создать файл robots.txt , можно воспользоваться любым текстовым редактором, например Блокнотом . Как только вы открыли новый текстовый документ, вы уже начали создание robots.txt, осталось только составить его содержимое, в зависимости от ваших требований, и сохранить в виде текстового файла с названием robots в формате txt . Все просто, и создание файла robots.txt не должно вызвать проблем даже у новичков. О том, как составить robots.txt и что писать в роботсе на примерах покажу ниже.
Cоздать robots.txt онлайн
Вариант для ленивых — создать роботс онлайн и скачать файл robots.txt уже в готовом виде. Создание robots txt онлайн предлагает множество сервисов, выбор за вами. Главное — четко понимать, что будет запрещено и что разрешено, иначе создание файла robots.txt online может обернуться трагедией , которую потом может быть сложно исправить. Особенно, если в поиск попадет то, что должно было быть закрытым. Будьте внимательны — проверьте свой файл роботс, прежде чем выгружать его на сайт. Все же пользовательский файл robots.txt точнее отражает структуру ограничений, чем тот, что был сгенерирован автоматически и скачан с другого сайта. Читайте дальше, чтобы знать, на что обратить особое внимание при редактировании robots.txt.
Редактирование robots.txt
После того, как вам удалось создать файл robots.txt онлайн или своими руками, вы можете редактировать robots.txt . Изменить его содержимое можно как угодно, главное — соблюдать некоторые правила и синтаксис robots.txt. В процессе работы над сайтом, файл роботс может меняться, и если вы производите редактирование robots.txt, то не забывайте выгружать на сайте обновленную, актуальную версию файла со всем изменениями. Далее рассмотрим правила настройки файла, чтобы знать, как изменить файл robots.txt и «не нарубить дров».
Правильная настройка robots.txt
Правильная настройка robots.txt позволяет избежать попадания частной информации в результаты поиска крупных поисковых систем. Однако, не стоит забывать, что команды robots.txt не более чем руководство к действию, а не защита . Роботы надежных поисковых систем, вроде Яндекс или Google, следуют инструкциям robots.txt, однако прочие роботы могут легко игнорировать их. Правильное понимание и применение robots.txt — залог получения результата.
Чтобы понять, как сделать правильный robots txt , для начала необходимо разобраться с общими правилами, синтаксисом и директивами файла robots.txt.
Правильный robots.txt начинается с директивы User-agent , которая указывает, к какому роботу обращены конкретные директивы.
Примеры User-agent в robots.txt:
# Указывает директивы для всех роботов одновременно User-agent: * # Указывает директивы для всех роботов Яндекса User-agent: Yandex # Указывает директивы для только основного индексирующего робота Яндекса User-agent: YandexBot # Указывает директивы для всех роботов Google User-agent: Googlebot
Учитывайте, что подобная настройка файла robots.txt указывает роботу использовать только директивы, соответствующие user-agent с его именем.
Пример robots.txt с несколькими вхождениями User-agent:
# Будет использована всеми роботами Яндекса User-agent: Yandex Disallow: /*utm_ # Будет использована всеми роботами Google User-agent: Googlebot Disallow: /*utm_ # Будет использована всеми роботами кроме роботов Яндекса и Google User-agent: * Allow: /*utm_
Директива User-agent создает лишь указание конкретному роботу, а сразу после директивы User-agent должна идти команда или команды с непосредственным указанием условия для выбранного робота. В примере выше используется запрещающая директива «Disallow», которая имеет значение «/*utm_». Таким образом, закрываем все . Правильная настройка robots.txt запрещает наличие пустых переводов строки между директивами «User-agent», «Disallow» и директивами следующими за «Disallow» в рамках текущего «User-agent».
Пример неправильного перевода строки в robots.txt:
Пример правильного перевода строки в robots.txt:
User-agent: Yandex Disallow: /*utm_ Allow: /*id= User-agent: * Disallow: /*utm_ Allow: /*id=
Как видно из примера, указания в robots.txt поступают блоками , каждый из которых содержит указания либо для конкретного робота, либо для всех роботов «*».
Кроме того, важно соблюдать правильный порядок и сортировку команд в robots.txt при совместном использовании директив, например «Disallow» и «Allow». Директива «Allow» — разрешающая директива, является противоположностью команды robots.txt «Disallow» — запрещающей директивы.
Пример совместного использования директив в robots.txt:
User-agent: * Allow: /blog/page Disallow: /blog
Данный пример запрещает всем роботам индексацию всех страниц, начинающихся с «/blog», но разрешает индексации страниц, начинающиеся с «/blog/page».
Прошлый пример robots.txt в правильной сортировке:
User-agent: * Disallow: /blog Allow: /blog/page
Сначала запрещаем весь раздел, потом разрешаем некоторые его части.
Еще один правильный пример robots.txt с совместными директивами:
User-agent: * Allow: / Disallow: /blog Allow: /blog/page
Обратите внимание на правильную последовательность директив в данном robots.txt.
Директивы «Allow» и «Disallow» можно указывать и без параметров, в этом случае значение будет трактоваться обратно параметру «/».
Пример директивы «Disallow/Allow» без параметров:
User-agent: * Disallow: # равнозначно Allow: / Disallow: /blog Allow: /blog/page
Как составить правильный robots.txt и как пользоваться трактовкой директив — ваш выбор. Оба варианта будут правильными. Главное — не запутайтесь.
Для правильного составления robots.txt необходимо точно указывать в параметрах директив приоритеты и то, что будет запрещено для скачивания роботам. Более полно использование директив «Disallow» и «Allow» мы рассмотрим чуть ниже, а сейчас рассмотрим синтаксис robots.txt. Знание синтаксиса robots.txt приблизит вас к тому, чтобы создать идеальный robots txt своими руками .
Синтаксис robots.txt
Роботы поисковых систем добровольно следуют командам robots.txt — стандарту исключений для роботов, однако не все поисковые системы трактуют синтаксис robots.txt одинаково. Файл robots.txt имеет строго определённый синтаксис, но в то же время написать robots txt не сложно, так как его структура очень проста и легко понятна.
Вот конкретные список простых правил, следуя которым, вы исключите частые ошибки robots.txt :
- Каждая директива начинается с новой строки;
- Не указывайте больше одной директивы в одной строке;
- Не ставьте пробел в начало строки;
- Параметр директивы должен быть в одну строку;
- Не нужно обрамлять параметры директив в кавычки;
- Параметры директив не требуют закрывающих точки с запятой;
- Команда в robots.txt указывается в формате — [Имя_директивы]:[необязательный пробел][значение][необязательный пробел];
- Допускаются комментарии в robots.txt после знака решетки #;
- Пустой перевод строки может трактоваться как окончание директивы User-agent;
- Директива «Disallow: » (с пустым значением) равнозначна «Allow: /» — разрешить все;
- В директивах «Allow», «Disallow» указывается не более одного параметра;
- Название файла robots.txt не допускает наличие заглавных букв, ошибочное написание названия файла — Robots.txt или ROBOTS.TXT;
- Написание названия директив и параметров заглавными буквами считается плохим тоном и если по стандарту, robots.txt и нечувствителен к регистру, часто к нему чувствительны имена файлов и директорий;
- Если параметр директивы является директорией, то перед название директории всегда ставится слеш «/», например: Disallow: /category
- Слишком большие robots.txt (более 32 Кб) считаются полностью разрешающими, равнозначными «Disallow: »;
- Недоступный по каким-либо причинам robots.txt может трактоваться как полностью разрешающий;
- Если robots.txt пустой, то он будет трактоваться как полностью разрешающий;
- В результате перечисления нескольких директив «User-agent» без пустого перевода строки, все последующие директивы «User-agent», кроме первой, могут быть проигнорированы;
- Использование любых символов национальных алфавитов в robots.txt не допускается.
Поскольку разные поисковые системы могут трактовать синтаксис robots.txt по-разному, некоторые пункты можно опустить. Так например, если прописать несколько директив «User-agent» без пустого перевода строки, все директивы «User-agent» будут восприняты корректно Яндексом, так как Яндекс выделяет записи по наличию в строке «User-agent».
В роботсе должно быть указано строго только то, что нужно, и ничего лишнего. Не думайте, как прописать в robots txt все , что только можно и чем его заполнить. Идеальный robots txt — это тот, в котором меньше строк, но больше смысла. «Краткость — сестра таланта». Это выражение здесь как нельзя кстати.
Как проверить robots.txt
Для того, чтобы проверить robots.txt на корректность синтаксиса и структуры файла, можно воспользоваться одной из онлайн-служб. К примеру, Яндекс и Google предлагают собственные сервисы для вебмастеров, которые включают анализ robots.txt:
Проверка файла robots.txt в Яндекс.Вебмастер: http://webmaster.yandex.ru/robots.xml
Для того, чтобы проверить robots.txt онлайн необходимо загрузить robots.txt на сайт в корневую директорию . Иначе, сервис может сообщить, что не удалось загрузить robots.txt . Рекомендуется предварительно проверить robots.txt на доступность по адресу где лежит файл, например: ваш_сайт.ru/robots.txt.
Кроме сервисов проверки от Яндекс и Google, существует множество других онлайн валидаторов robots.txt.
Robots.txt vs Яндекс и Google
Есть субъективное мнение, что указание отдельного блока директив «User-agent: Yandex» в robots.txt Яндекс воспринимает более позитивно, чем общий блок директив с «User-agent: *». Аналогичная ситуация robots.txt и Google. Указание отдельных директив для Яндекс и Google позволяет управлять индексацией сайта через robots.txt. Возможно, им льстит персонально обращение, тем более, что для большинства сайтов содержимое блоков robots.txt Яндекса, Гугла и для других поисковиков будет одинаково. За редким исключением, все блоки «User-agent» будут иметь стандартный для robots.txt набор директив. Так же, используя разные «User-agent» можно установить запрет индексации в robots.txt для Яндекса , но, например не для Google.
Отдельно стоит отметить, что Яндекс учитывает такую важную директиву, как «Host», и правильный robots.txt для яндекса должен включать данную директиву для указания главного зеркала сайта. Подробнее директиву «Host» рассмотрим ниже.
Запретить индексацию: robots.txt Disallow
Disallow — запрещающая директива , которая чаще всего используется в файле robots.txt. Disallow запрещает индексацию сайта или его части, в зависимости от пути, указанного в параметре директивы Disallow.
Пример как в robots.txt запретить индексацию сайта:
User-agent: * Disallow: /
Данный пример закрывает от индексации весь сайт для всех роботов.
В параметре директивы Disallow допускается использование специальных символов * и $:
* — любое количество любых символов, например, параметру /page* удовлетворяет /page, /page1, /page-be-cool, /page/kak-skazat и т.д. Однако нет необходимости указывать * в конце каждого параметра, так как например, следующие директивы интерпретируются одинаково:
User-agent: Yandex Disallow: /page User-agent: Yandex Disallow: /page*
$ — указывает на точное соответствие исключения значению параметра:
User-agent: Googlebot Disallow: /page$
В данном случае, директива Disallow будет запрещать /page, но не будет запрещать индексацию страницы /page1, /page-be-cool или /page/kak-skazat.
Если закрыть индексацию сайта robots.txt , в поисковые системы могут отреагировать на так ход ошибкой «Заблокировано в файле robots.txt» или «url restricted by robots.txt» (url запрещенный файлом robots.txt). Если вам нужно запретить индексацию страницы , можно воспользоваться не только robots txt, но и аналогичными html-тегами:
- - не индексировать содержимое страницы;
- - не переходить по ссылкам на странице;
- - запрещено индексировать содержимое и переходить по ссылкам на странице;
- — аналогично content=»none».
Разрешить индексацию: robots.txt Allow
Allow — разрешающая директива и противоположность директиве Disallow. Эта директива имеет синтаксис, сходный с Disallow.
Пример, как в robots.txt запретить индексацию сайта кроме некоторых страниц:
User-agent: * Disallow: / Allow: /page
Запрещается индексировать весь сайт , кроме страниц, начинающихся с /page.
Disallow и Allow с пустым значением параметра
Пустая директива Disallow:
User-agent: * Disallow:
Не запрещать ничего или разрешить индексацию всего сайта и равнозначна:
User-agent: * Allow: /
Пустая директива Allow:
User-agent: * Allow:
Разрешить ничего или полный запрет индексации сайта, равнозначно:
User-agent: * Disallow: /
Главное зеркало сайта: robots.txt Host
Директива Host служит для указания роботу Яндекса главного зеркала Вашего сайта . Из всех популярных поисковых систем, директива Host распознаётся только роботами Яндекса . Директива Host полезна в том случае, если ваш сайт доступен по нескольким , например:
Mysite.ru mysite.com
Или для определения приоритета между:
Mysite.ru www.mysite.ru
Роботу Яндекса можно указать, какое зеркало является главным . Директива Host указывается в блоке директивы «User-agent: Yandex» и в качестве параметра, указывается предпочтительный адрес сайта без «http://».
Пример robots.txt с указанием главного зеркала:
User-agent: Yandex Disallow: /page Host: mysite.ru
В качестве главного зеркала указывается доменное имя mysite.ru без www. Таки образом, в результатах поиска буде указан именно такой вид адреса.
User-agent: Yandex Disallow: /page Host: www.mysite.ru
В качестве основного зеркала указывается доменное имя www.mysite.ru.
Директива Host в файле robots.txt может быть использована только один раз, если же директива Хост будет указана более одного раза, учитываться будет только первая, прочие директивы Host будут игнорироваться.
Если вы хотите указать главное зеркало для робота Google, воспользуйтесь сервисом Google Инструменты для вебмастеров.
Карта сайта: robots.txt sitemap
При помощи директивы Sitemap, в robots.txt можно указать расположение на сайте .
Пример robots.txt с указанием адреса карты сайта:
User-agent: * Disallow: /page Sitemap: http://www.mysite.ru/sitemap.xml
Указание адреса карты сайта через директиву Sitemap в robots.txt позволяет поисковому роботу узнать о наличии карты сайта и начать ее индексацию.
Директива Clean-param
Директива Clean-param позволяет исключить из индексации страницы с динамическими параметрами. Подобные страницы могут отдавать одинаковое содержимое, имея различные URL страницы. Проще говоря, будто страница доступна по разным адресам. Наша задача убрать все лишние динамические адреса, которых может быть миллион. Для этого исключаем все динамические параметры, используя в robots.txt директиву Clean-param .
Синтаксис директивы Clean-param:
Clean-param: parm1[&parm2&parm3&parm4&..&parmn] [Путь]
Рассмотрим на примере страницы со следующим URL:
Www.mysite.ru/page.html?&parm1=1&parm2=2&parm3=3
Пример robots.txt Clean-param:
Clean-param: parm1&parm2&parm3 /page.html # только для page.html
Clean-param: parm1&parm2&parm3 / # для всех
Директива Crawl-delay
Данная инструкция позволяет снизить нагрузку на сервер, если роботы слишком часто заходят на ваш сайт. Данная директива актуальна в основном для сайтов с большим объемом страниц.
Пример robots.txt Crawl-delay:
User-agent: Yandex Disallow: /page Crawl-delay: 3
В данном случае мы «просим» роботов яндекса скачивать страницы нашего сайта не чаще, чем один раз в три секунды. Некоторые поисковые системы поддерживают формат дробных чисел в качестве параметра директивы Crawl-delay robots.txt .