Php short tags not working. Complex password check
Last update on November 27 2019 07:10:59 (UTC / GMT +8 hours)
PHP opening and closing Tags syntax
There are four different pairs of opening and closing tags which can be used in php. Here is the list of tags.
- Default syntax
- Short open Tags
- Omit the PHP closing tag at the end of the file
Default syntax
The default syntax starts with "".
Example:
Short open Tags
The short tags starts with "". Short style tags are only available when they are enabled in php.ini configuration file on servers.
Example:
Omit the PHP closing tag at the end of the file
It is recommended that a closing PHP tag shall be omitted in a file containing only PHP code so that occurrences of accidental whitespace or new lines being added after the PHP closing tag, which may start output buffering causing uncalled for effects can be avoided.
Example:
PHP Statement separation
In PHP, statements are terminated by a semicolon (;) like C or Perl. The closing tag of a block of PHP code automatically implies a semicolon, there is no need to have a semicolon terminating the last line of a PHP block.
Rules for statement separation
- a semicolon
- AND / OR
- a closing PHP tag
Valid Codes
In the above example, both semicolon (;) and a closing PHP tag are present.
In the above example, there is no semicolon (;) after the last instruction but a closing PHP tag is present.
In the above example, there is a semicolon (;) in the last instruction but there is no closing PHP tag.
PHP Case sensitivity
In PHP the user defined functions, classes, core language keywords (for example if, else, while, echo etc.) are case-insensitive. Therefore the three echo statements in the following example are equal.
Example - 1
"); ECHO (" We are learning PHP case sensitivity
"); EcHo (" We are learning PHP case sensitivity
");
?>
We are learning PHP case sensitivity We are learning PHP case sensitivity We are learning PHP case sensitivity
On the other hand, all variables are case-sensitive.
Consider the following example. Only the first statement display the value as $ amount because $ amount, $ AMOUNT, $ amoUNT are three different variables.
Example - 2
"); echo (" The Amount is: $ AMOUNT
"); echo (" The Amount is: $ amoUNT
");
?>
The Amount is: 200 The Amount is: The Amount is:
PHP whitespace insensitivity
In general, whitespace is not visible on the screen, including spaces, tabs, and end-of-line characters i.e. carriage returns. In PHP whitespace doesn "t matter in coding. You can break a single line statement to any number of lines or number of separate statements together on a single line.
The following two examples are same:
Example:
"; echo" His Class is: $ class and Roll No. is $ roll_no ";) student_info (" David Rayy "," V ", 12)?\u003e
Example: Advance whitespace insensitivity
"; echo" His Class is: $ class and Roll No. is $ roll_no ";) student_info (" David Rayy "," V ", 12)?\u003e
The Name of student is: David Rayy His Class is: V and Roll No. is 12
Example: Whitespace insensitivity with tabs and spaces
In the following example spaces and tabs are used in a numeric operation, but in both cases, $ xyz returns the same value.
"; // tabs and spaces $ xyz \u003d 11 + 12; echo $ xyz;?\u003e
PHP: Single line and Multiple lines Comments
Single line comment
PHP supports the following two different way of commenting.
# This is a single line comment.
// This is another way of single line comment.
Example:
Multiple lines comments
PHP supports "C", style comments. A comment starts with the character pair / * and terminates with the character pair * /.
/ * This is a multiple comment testing,
and these lines will be ignored
at the time of execution * /
Example:
Multiple lines comments can not be nested
First PHP Script
Here is the first PHP script which will display "Hello World ..." in the web browser.
& lt? php echo "Hello World ..."; ?\u003e
The tags tell the web server to treat everything inside the tags as PHP code to run. The code is very simple. It uses an in-build PHP function "echo" to display the text "Hello World ..." in the web page. Everything outside these tags is sent directly to the browser.
Pictorial presentation
Combining PHP and HTML
PHP syntax is applicable only within PHP tags.
PHP can be embedded in HTML and placed anywhere in the document.
When PHP is embedded in HTML documents and PHP parses this document it interpreted the section enclosed with an opening tag () of PHP and ignore the rest parts of the document.
PHP and HTML are seen together in the following example.
Practice here online:
Regular expressions are a very useful tool for developers. With their help, you can find, define or replace text, words or any other characters. Today's article has collected 15 of the most useful regular expressions that any web developer will need.
Introduction to Regular Expressions
Many novice developers find regular expressions very difficult to understand and use. In fact, everything is not as complicated as it might seem. Before we jump directly into regular expressions, with their useful and versatile code, let's take a look at the basics:
Regular Expression Syntax
| Regular expression | Means |
| foo | The string "foo" |
| ^ foo | The line starts with “foo” |
| foo $ | The line ends with "foo" |
| ^ foo $ | "Foo" occurs only once per line |
| a, b, or c | |
| any lowercase character | |
| [^ A-Z] | any non-uppercase character |
| (gif | jpg) | Means both "gif" and "jpeg" |
| + | One or more lowercase characters |
| Any digit, period, or minus sign | |
| ^{1,}$ | Any word, at least one letter, number or _ |
| ()() | wy, wz, xy, or xz |
| (^ A-Za-z0-9) | Any character (not a number or a letter) |
| ({3}|{4}) | Means three letters or 4 numbers |
PHP functions for regular expressions
| Function | Description |
| preg_match () | The preg_match () function searches for a string according to a given pattern, returns true if the string is found and false, otherwise |
| preg_match_all () | Preg_match_all () function finds all occurrences of a patterned string |
| preg_replace () | The preg_replace () function works in the same way as ereg_replace (), except that regular expressions can be used both to specify the search pattern and for the string to replace the found value with. |
| preg_split () | The preg_split () function is the same as split (), except that the regular expression can be used as a parameter for the search pattern. |
| preg_grep () | The preg_grep () function searches for all elements of the input array, returning all elements that match the regular expression pattern. |
| preg_quote () | Escapes regular expression characters |
Domain name check
Checking if the string is correct domain name
$ url \u003d "http://komunitasweb.com/"; if (preg_match ("/^(http|https|ftp)://(*(?:.*)+):?(d+)?/?/i", $ url)) (echo "Your url is ok . ";) else (echo" Wrong url. ";)
Word highlighting in text
This is a very useful regular expression, you can use it to find the desired word and highlight it. Especially useful for displaying search results.
$ text \u003d "Sample sentence from KomunitasWeb, regex has become popular in web programming. Now we learn regex. According to wikipedia, Regular expressions (abbreviated as regex or regexp, with plural forms regexes, regexps, or regexen) are written in a formal language that can be interpreted by a regular expression processor "; $ text \u003d preg_replace ("/ b (regex) b / i", " 1", $ text); echo $ text;
Highlighting search results in a WordPress blog
As mentioned in the previous example, this code example is useful for search results and there is a great way to implement this feature in a wordpress blog.
Open your search.php file and find the the_title () function. Replace it with the following code:
Echo $ title;
Now, above this line, add this code:
\0", $ title);?\u003e
Save the search.php file, and open style.css. Add the following line:
Strong.search-excerpt (background: yellow;)
Retrieving all images from an HTML document
If you ever needed to get all the images from a web page, this code should be there.You can easily create an image loader using cURL features
$ images \u003d array (); preg_match_all ("/ (img | src) \u003d (" | \\ ") [^" \\ "\u003e] + / i", $ data, $ media); unset ($ data); $ data \u003d preg_replace ("/ (img | src) (" | \\ "| \u003d" | \u003d \\ ") (. *) / i", "$ 3", $ media); foreach ($ data as $ url) ($ info \u003d pathinfo ($ url); if (isset ($ info ["extension"])) (if (($ info ["extension"] \u003d\u003d "jpg") || ($ info ["extension"] \u003d\u003d "jpeg") || ($ info ["extension"] \u003d\u003d "gif") || ($ info ["extension"] \u003d\u003d "png")) array_push ($ images, $ url);))
Remove duplicate words (not case sensitive)
During typing, do words often repeat? This regular expression will help.
$ text \u003d preg_replace ("/ s (w + s) 1 / i", "$ 1", $ text);
Removing duplicate punctuation
The same, only for punctuation. Say goodbye to double commas.
$ text \u003d preg_replace ("/.+/ i", ".", $ text);
Search for XML / HTML tags
This is a simple function that takes two arguments. The first is the tag you need to find, and the second is a variable containing XML or HTML. Again, this function is very convenient to use with cURL.
Function get_tag ($ tag, $ xml) ($ tag \u003d preg_quote ($ tag); preg_match_all ("(<".$tag."[^>]*>(.*?). ")", $ xml, $ matches, PREG_PATTERN_ORDER); return $ matches; )
Finding XHTML / XML tags with a specific attribute value
This function is very similar to the previous one, except that you can give the tag the desired attribute. For example, you can easily find
Function get_tag ($ attr, $ value, $ xml, $ tag \u003d null) (if (is_null ($ tag)) $ tag \u003d "\\ w +"; else $ tag \u003d preg_quote ($ tag); $ attr \u003d preg_quote ($ attr); $ value \u003d preg_quote ($ value); $ tag_regex \u003d "/<(".$tag.")[^>] * $ attr \\ s * \u003d \\ s * "." (["\\"]) $ value \\\\ 2 [^\u003e] *\u003e (. *?)<\/\\1>/ "preg_match_all ($ tag_regex, $ xml, $ matches, PREG_PATTERN_ORDER); return $ matches;)
Finding Hexadecimal Color Values
Another useful tool for web developers! It allows you to find / check the hexadecimal color value.
$ string \u003d "# 555555"; if (preg_match ("/ ^ # (? :(? :( 3)) (1,2)) $ / i", $ string)) (echo "example 6 successful.";)
Search article title
This piece of code will find and display the text inside the tags
$ fp \u003d fopen ("http://www.catswhocode.com/blog", "r"); while (! feof ($ fp)) ($ page. \u003d fgets ($ fp, 4096);) $ titre \u003d eregi ("
Parsing Apache Logs
Most of the sites are running on the well-known Apache web server. If your site is one of them, why not use PHP and regular expressions to parse Apache logs?
// Logs: Apache web server // Successful hits to HTML files only. Useful for counting the number of page views. "^ ((? # client IP or domain name) S +) s + ((? # basic authentication) S + s + S +) s + [((? # date and time) [^]] +)] s +" (?: GET | POST | HEAD) ((? #File) / [^? "] + ?. html?) ?? ((? # Parameters) [^?"] +)? HTTP / + "s + (? # Status code) 200s + ((? # Bytes transferred) [- 0-9] +) s +" ((? # Referrer) [^ "] *)" s + "((? # User agent ) [^ "] *)" $ "// Logs: Apache web server // 404 errors only" ^ ((? # Client IP or domain name) S +) s + ((? # Basic authentication) S + s + S +) s + [((? # date and time) [^]] +)] s + "(?: GET | POST | HEAD) ((? #file) [^?"] +) ?? ((? # parameters) [ ^? "] +)? HTTP / + "s + (? # Status code) 404s + ((? # Bytes transferred) [- 0-9] +) s +" ((? # Referrer) [^ "] *)" s + "((? # User agent ) [^ "] *)" $ "
Replacing double quotes with smart quotes
If you are a typography lover, you will love this regex that replaces regular double quotes, with smart quotes. A similar regex is used by wordpress in the page content.
Preg_replace ("B" b ([^ "x84x93x94rn] +) b" B ","? 1? ", $ Text);
Complex password check
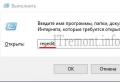
This regex will make sure that at least six characters, numbers, hyphens, and underscores are entered in the text box.
The text box must contain at least one uppercase, one lowercase, and one number.
"A (? \u003d [-_ a-zA-Z0-9] *?) (? \u003d [-_ a-zA-Z0-9] *?) (? \u003d [-_ a-zA-Z0-9] *?) [-_a-zA-Z0-9] (6,) z "
WordPress: Using a Regular Expression to Get Images from a Post
Since many of you are WordPress users, you may need a code that allows you to get all the images from the text of the article and display them.
In order to use this code, just paste it into any file of your theme.
post_content; $ szSearchPattern \u003d "~ ] * /\u003e ~ "; // Run preg_match_all to grab all the images and save the results in $ aPics preg_match_all ($ szSearchPattern, $ szPostContent, $ aPics); // Check to see if we have at least 1 image $ iNumberOfPics \u003d count ($ aPics); if ($ iNumberOfPics\u003e 0) (// Now here you would do whatever you need to do with the images // For this example the images are just displayed for ($ i \u003d 0; $ i< $iNumberOfPics ; $i++) {
echo $aPics[$i];
};
};
endwhile;
endif;
?>
Generating automatic emoticons
Another feature used in wordpress is to automatically replace emoticons with a smiley picture.
$ texte \u003d "A text with a smiley :-)"; echo str_replace (":-)", "  ", $ texte);
", $ texte);
JavaScript is blocked in your browser. Please enable JavaScript for the site to work!
strip_tags
(PHP 3\u003e \u003d 3.0.8, PHP 4, PHP 5)
strip_tags - Removes HTML and PHP tags from stringDescription
string strip_tags (string str [, string allowable_tags])This function returns the string str from which the HTML and PHP tags have been removed. To remove tags, an automaton is used similar to that used in the function fgetss () .
The optional second argument can be used to specify tags that should not be removed.
AttentionComment: The allowable_tags argument was added in PHP 3.0.13 and PHP 4.0b3. FROM pHP versions 0 also removes HTML comments.
Because strip_tags () does not check the correctness of HTML code, incomplete tags can lead to the removal of text that is not included in tags.
Example 1. Example of use strip_tags ()
$ text \u003d "Paragraph.
Some more text "; echo strip_tags ($ text); echo" \\ n \\ n ------- \\ n "; // don't deleteEcho strip_tags ($ text, "
"); // Allow ,, echo strip_tags ($ text, " ");
This example will output:
Paragraph. Some more text -------
Paragraph.
Some more text
AttentionThis function does not change the attributes of the tags specified in the allowable_tags argument, including style and onmouseover.
Since PHP 5.0.0 strip_tags () safe for processing data in binary form.
This function has a significant drawback - it is gluing words when removing tags. In addition, the function has vulnerabilities. An alternative function analogous to strip_tags:
c "* -" dirty "html is processed correctly, when symbols can be found in the tag attribute values< > * - broken html is processed correctly * - comments, scripts, styles, PHP, Perl, ASP code, MS Word tags, CDATA are cut out * - text is automatically formatted if it contains html code * - protection against forgeries like: "<
See also function description
When the PHP interpreter parses the file, it looks for tags that indicate where the PHP code starts and ends. Anything outside a pair of opening and closing tags will be ignored by the interpreter (i.e., it will simply be given to the web server as it is). For example, a file passed to the PHP interpreter has the following code:
This will be ignored by the interpreter and will simply be given as is, first to the web server, which in turn will give it to the browser.
This will also be ignored by the interpreter and will simply be passed to the web server as it is.
If the file contains only PHP-code or it is located at the very end of the file, that is, there is nothing after it, then it is preferable to omit the closing tag (do not specify). This avoids adding random whitespace after the PHP end tag, which can cause unwanted effects.
PHP also allows the use of a short opening tag
Whitespace characters
In PHP code you can use whitespace characters: spaces, tabs and line breaks. The number of whitespace characters is not limited and depends on the preferences of the programmer, whose main goal is to create a clear and easy-to-read program text (source code).
The example below shows PHP code that uses whitespace:
The example code could be written on a single line without using whitespace, but this code would be less readable: